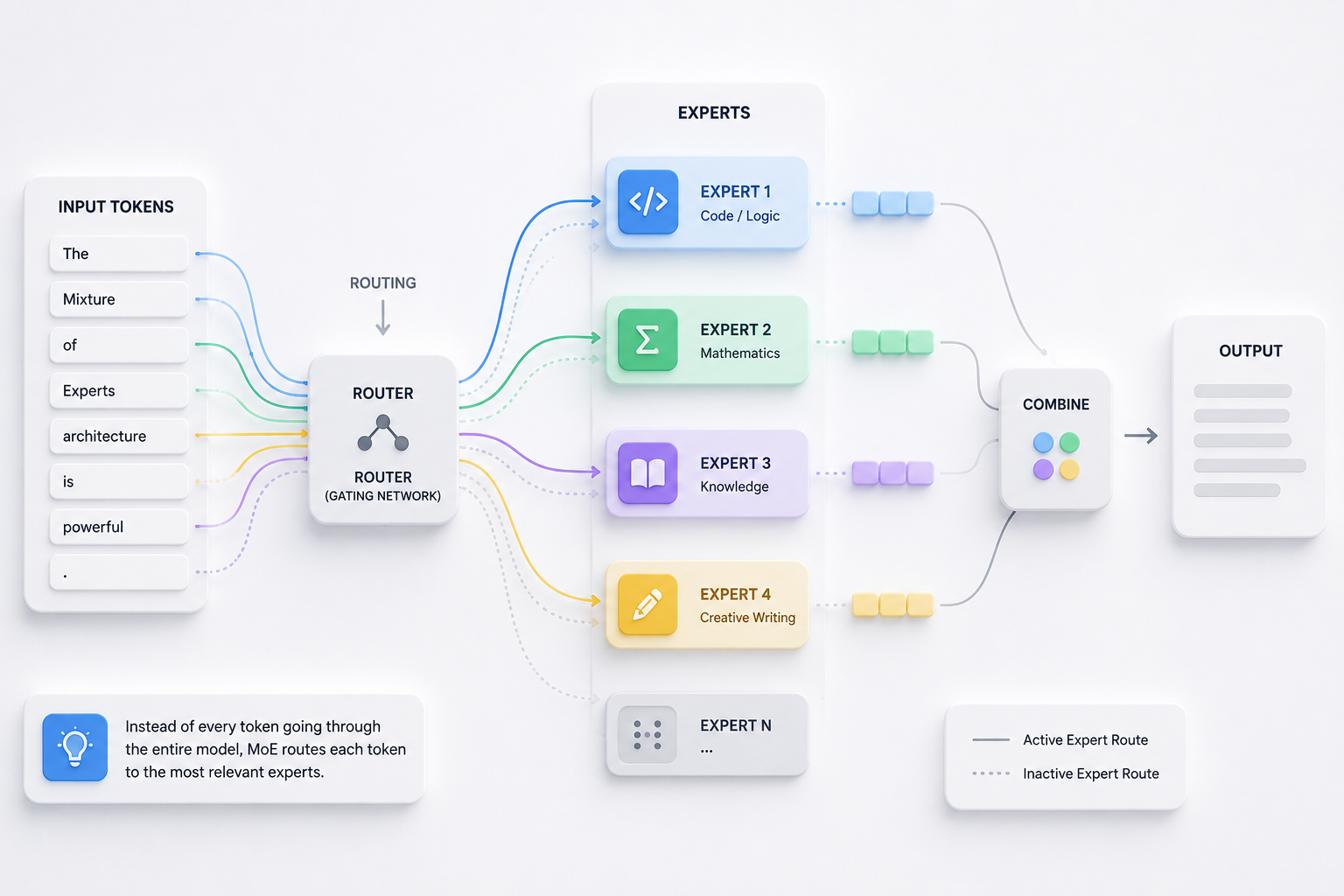
The phrase mixture of experts explained why biggest AI models aren’t monolithic often comes up in AI discussions, and there’s a good reason for that. Today’s leading AI systems, like GPT-4, Gemini, and Claude, don’t operate as a single massive neural network processing every token through every parameter.
Instead, they use a clever setup called a Mixture of Experts (MoE). This divides a large model into specialized sub-networks where only some parameters activate for any given input. Thus, you’re accessing the intelligence of a trillion-parameter model without the enormous compute cost.
Understanding this setup is crucial. It explains why API costs are dropping, why open-source models are progressing rapidly, and why AI pricing battles are intensifying faster than expected.
How Mixture of Experts Works
Here’s the deal: a traditional “dense” model activates every parameter for every input, which is costly. A Mixture of Experts model works differently.
The router network: Think of it as a traffic cop at each layer, deciding which “expert” sub-networks should handle the current input. Typically, just 2 out of 8, 16, or even 64 experts activate per token. The router determines which experts excel at what.
Sparse activation: Even if a model has 1.8 trillion parameters, only 200 billion activate for any forward pass. You get the full parameter count’s knowledge but at the cost of a much smaller model.
Here’s how it flows:
- An input token hits a transformer layer.
- The router checks the token’s representation.
- It scores which experts should handle it.
- The top-k experts (generally 2) tackle the token.
- Their outputs get weighted and combined.
- The result moves to the next layer.
This isn’t a new idea. The original MoE concept emerged in the 1990s thanks to Geoffrey Hinton and his team. But today’s hardware and training techniques have finally made it viable on a large scale.
The mixture of experts explained why biggest AI models opt for sparse routing becomes clear when you do the math. A dense 1.8-trillion-parameter model would need about 10 times the compute of a sparse MoE model with the same parameter count. That’s a game changer.
Practical Example
Consider a large-scale customer service AI deployed by a multinational corporation. It uses an MoE model to efficiently handle diverse customer queries in multiple languages. When a customer asks a question in French about a technical issue, the router quickly identifies and activates experts specialized in French language processing and technical support. This targeted activation ensures the response is both linguistically accurate and technically sound, showcasing the MoE model’s ability to leverage specialized knowledge without engaging unnecessary resources.
Clarifying Steps: Building a MoE Model
To build an effective MoE model, follow these steps:
- Define the tasks: Identify the range of tasks the model will handle. This helps in determining necessary expert specializations.
- Select a base architecture: Choose a transformer architecture as the foundation since MoE models typically build on transformers.
- Design the experts: Create sub-networks that specialize in different domains, such as language processing, technical knowledge, or customer service.
- Implement the router network: Develop a system to efficiently route inputs to the appropriate experts.
- Training: Train the model using a diverse dataset to ensure comprehensive coverage of potential queries.
- Testing and optimization: Continuously test the model’s performance and adjust expert specializations and routing strategies as needed.
Why GPT-4, Gemini, and Claude Use MoE
Frontier labs didn’t randomly choose MoE architectures. Three forces led them in that direction.
Compute economics: Pushing dense models past a certain size becomes extremely costly. Google’s Switch Transformer research showed that MoE models could match dense models’ quality while using much less training compute. Plus, inference costs drop because fewer parameters activate per request.
Scaling laws: Studies from DeepMind and OpenAI show that model quality improves with more parameters—up to a point with dense setups. MoE allows adding more parameters (and thus more knowledge) without inflating compute costs. Consequently, labs can create larger models without breaking the bank.
Specialization benefits: Different experts naturally excel at handling different kinds of knowledge. One expert might handle code well, another multilingual tasks, and others math. This specialization often yields better results than making every parameter a generalist.
Meanwhile, the rumored GPT-4 architecture reportedly involves 8 experts with around 220 billion parameters each. Google’s Gemini family uses MoE methods too. Although Claude’s exact architecture isn’t confirmed by Anthropic, industry analysis suggests MoE components are involved.
The mixture of experts explained why biggest AI models run with this method because it’s about efficiency. Dense models hit a ceiling, and MoE found a way past it.
Scenario: Education Sector
Imagine an educational platform using an MoE model to personalize learning experiences for students worldwide. A student struggling with calculus could trigger the activation of specific experts adept at mathematical problem-solving, while another student working on an essay might engage experts in language and writing. This tailored approach not only enhances learning outcomes but also optimizes resource allocation, demonstrating MoE’s versatility across different domains.
Practical Tips for Implementation
For educational institutions looking to implement MoE models, consider the following:
- Identify diverse student needs: Use data analytics to understand the varying challenges students face across subjects.
- Develop expert modules: Create specialized experts for different subjects and learning styles.
- Integrate adaptive learning pathways: Allow the model to adaptively route students through content based on their progress and performance.
- Monitor and refine: Regularly assess the effectiveness of expert routing and adjust strategies to improve educational outcomes.
MoE vs. Dense Models: Comparing Architectures
To understand why the mixture of experts explained why biggest AI models favor sparse routing, a side-by-side comparison helps. Here’s how these architectures compare:
| Feature | Dense Model | MoE Model |
|---|---|---|
| Total parameters | 70B–540B typical | 600B–1.8T+ typical |
| Active parameters per token | All of them | 10–25% of total |
| Training compute | Scales linearly with params | Sub-linear scaling |
| Inference cost per token | Higher | Significantly lower |
| Memory requirements | Proportional to params | Full model must fit in memory |
| Specialization | All params are generalist | Experts develop specialties |
| Example models | LLaMA 70B, PaLM 540B | Mixtral 8x7B, GPT-4 (rumored) |
| Best suited for | Smaller deployments | Frontier-scale performance |
Key tradeoffs include:
- Memory overhead: MoE models use less compute per token, but the entire model needs memory space. A 1.8T-parameter MoE model demands massive GPU clusters, even if most parameters are idle during inference.
- Load balancing: If the router sends too many tokens to one expert, bottlenecks happen. Training needs careful auxiliary losses to keep expert use balanced.
- Communication costs: In distributed training, experts often live on different GPUs. Routing tokens across machines creates network overhead. However, this cost is way lower than running a similarly sized dense model.
Notably, the open-source scene is also on the MoE train. Mistral AI’s Mixtral 8x7B showed that a 46.7B total-parameter MoE model (with only 12.9B active parameters) could match dense models several times its active size. That was a big moment for accessible AI.
Practical Tip: Balancing Experts
For practitioners, managing load and ensuring balanced activation across experts is crucial. Implementing auxiliary loss functions that penalize uneven expert utilization can help maintain efficiency. This ensures no single expert becomes a bottleneck, allowing the model to perform optimally across diverse tasks.
Clarifying Steps: Load Balancing
To achieve effective load balancing in MoE models, consider these steps:
- Monitor expert utilization: Use metrics to track how often each expert is activated.
- Adjust router criteria: Refine the router’s decision-making process to distribute tasks more evenly.
- Implement dynamic routing: Allow the router to adaptively change routing strategies based on real-time performance data.
- Regularly update training data: Ensure the training data reflects the diversity of tasks the model will encounter, promoting balanced expert activation.
MoE Architecture and Model Pricing Wars
The mixture of experts explained why biggest AI models ties directly to your wallet. MoE architecture is why API prices are dropping.
The cost equation changed. When GPT-4 launched, its API pricing seemed steep. But MoE architecture lets OpenAI avoid running all 1.8 trillion parameters for your query. Only some activate, making the real compute cost per token much less than the total parameter count suggests.
This has set off a price war:
- OpenAI cut GPT-4 Turbo prices by about three times compared to the original GPT-4 pricing.
- Google rolled out Gemini 1.5 Pro with competitive per-token rates.
- Anthropic positioned Claude 3.5 Sonnet as a high-performing, cost-friendly option.
- Open-source MoE models like Mixtral add more pressure on pricing.
Moreover, MoE supports tiered product strategies. Labs can offer smaller, cheaper models (using fewer experts or smaller expert networks) alongside flagship models. Anthropic’s model lineup perfectly illustrates this—Haiku, Sonnet, and Opus likely represent different points on the MoE complexity spectrum.
Pricing implications go beyond API costs. Specifically, MoE makes self-hosting high-quality models more practical. While hefty hardware is still necessary, the inference compute per request drops enough to make the numbers work for more organizations.
Conversely, dense models can’t match the frontier on price. Running every parameter for every token just costs more. This is why the mixture of experts explained why biggest AI models line matters for anyone figuring out their AI infrastructure budget.
Tradeoff: Flexibility vs. Cost
Organizations must weigh the flexibility of open-source MoE models against the convenience and raw power of closed-source solutions. While open-source models offer customization and cost savings, closed-source APIs provide cutting-edge performance with minimal setup. The choice depends on specific business needs, technical expertise, and budget constraints.
Practical Tips for Cost Management
To manage costs effectively when utilizing MoE models, consider these strategies:
- Evaluate usage patterns: Analyze when and how often the model is used to optimize spending.
- Leverage tiered models: Use smaller, less expensive models for routine tasks and reserve high-performance models for critical operations.
- Consider hybrid deployment: Combine open-source models for cost savings with closed-source APIs for high-stakes tasks.
- Negotiate with providers: Engage with API providers for potential volume discounts or customized pricing plans based on your usage.
Open vs. Closed MoE Models
The MoE wave has intensified the open-source versus closed-source debate. Both sides use sparse architectures but offer different perks.
Closed-source advantages:
- Larger total parameter numbers (rumored 1T+ for GPT-4 and Gemini).
- Proprietary training data and tricks.
- More resources for router fine-tuning.
- Better load balancing across vast expert pools.
- Continuous improvements from user feedback.
Open-source advantages:
- Total architectural transparency.
- Community-led tweaks.
- Self-hosting removes per-token API expenses.
- Customizable expert routing for niche areas.
- No vendor lock-in headaches.
DeepSeek’s MoE models proved open-source MoE can punch above its weight. DeepSeek-V2 uses a novel multi-head latent attention mechanism paired with MoE to offer GPT-4-level performance at way lower costs. Similarly, DBRX by Databricks pushed open MoE architectures further.
Still, closed models hold the edge in raw power. The gap is closing, though, and the mixture of experts explained why biggest AI models aren’t monolithic applies to both camps.
Here’s how the competitive scene shapes up:
- For startups: Open MoE models like Mixtral provide stellar cost-efficiency.
- For enterprises: Closed APIs offer ease and cutting-edge quality.
- For researchers: Open architectures allow experimenting with routing strategies.
- For budget-conscious teams: Self-hosted MoE models cut recurring API fees.
Many organizations take a hybrid route. They send simple queries to smaller open MoE models and complex tasks to high-tier closed APIs. This maximizes the strengths of both worlds.
Practical Tip: Choosing the Right Model
When deciding between open and closed MoE models, consider the specific requirements of your application. For instance, if your work involves sensitive data, self-hosting an open-source model might be preferable for privacy reasons. Conversely, if you need the latest advancements and can afford it, a closed-source API could offer superior performance and support.
Scenario: Healthcare Industry
In the healthcare industry, choosing between open and closed MoE models can significantly impact data privacy and innovation. Hospitals might opt for open-source models to develop custom applications for patient data analysis, ensuring compliance with data protection regulations. On the other hand, pharmaceutical companies might leverage closed-source APIs for cutting-edge drug discovery processes, benefiting from the latest advancements in AI technology.
What’s Next for MoE and AI Architecture
The mixture of experts explained why biggest AI models story is still unfolding. Several trends are shaping MoE’s future.
Expert granularity is increasing. Early MoE models had 8 to 16 experts. New designs are trying hundreds or even thousands of fine-grained experts. This allows more precise routing and better specialization. So, models can build deeper skills in niche areas without losing range.
Routing is getting smarter. Current routers make token-level decisions. Future setups might route at the sequence or task level. Also, researchers are exploring dynamic routing strategies that change based on input difficulty or domain.
Hardware is adapting. NVIDIA, Google, and AMD are crafting chips with MoE workloads in mind. Specifically, faster inter-chip communication cuts the cost of routing tokens between experts on different GPUs. This hardware shift will make MoE even leaner.
Key developments to watch:
- Mixture of Agents—using multiple full models instead of sub-networks.
- Conditional computation going beyond expert selection.
- Dynamic expert creation during training.
- Cross-modal experts for text, image, and audio routing.
- Distillation techniques compressing MoE models into smaller dense models for edge use.
Importantly, MoE isn’t the only show in town. Researchers are exploring state-space models, retrieval-augmented approaches, and other paths. But for now, MoE reigns supreme at the frontier. The economics just make too much sense.
Scenario: Future Applications
Imagine a future where MoE models power autonomous vehicles. Each vehicle could dynamically route tasks such as navigation, object detection, and communication to specialized experts, optimizing performance and safety. This application highlights MoE’s potential to transform industries by enabling real-time, efficient processing of complex tasks.
Practical Steps for Future-Proofing
To stay ahead in the evolving MoE landscape, organizations can:
- Invest in scalable infrastructure: Prepare for increased expert granularity by ensuring your infrastructure can handle more complex routing and expert management.
- Stay updated on research: Regularly review academic and industry publications to keep abreast of the latest MoE advancements and incorporate them into your strategies.
- Participate in AI communities: Engage with open-source communities and forums to share insights and learn from others’ experiences with MoE models.
- Experiment with emerging technologies: Explore new developments like cross-modal experts and dynamic routing to assess their potential impact on your applications.
Conclusion
Understanding mixture of experts explained why biggest AI models aren’t monolithic totally reframes AI. These aren’t just huge brains. They’re smart collections of sub-networks, carefully routed for specific input types.
This architecture is why costs drop, performance rises, and competition gets tougher. It explains why API prices are tumbling and why open-source models are catching up with proprietary ones. Additionally, it shows why total parameter counts can mislead—active parameters are what count.
Your actionable next steps:
- Evaluate MoE-based models for your projects. Compare Mixtral, GPT-4, and Gemini on your specific needs rather than relying on broad benchmarks.
- Rethink cost assumptions. MoE architectures make top-tier performance possible without top-tier budgets.
- Experiment with open MoE models. Mixtral 8x7B and DeepSeek-V2 deliver surprisingly strong self-hosted performance.
- Keep an eye on routing innovations. Smarter routing will be key for the next wave of capabilities.
- Stay architecture-aware. Knowing whether a model uses MoE or dense architecture helps you anticipate its cost and performance profile.
The mixture of experts explained why biggest AI models use sparse routing isn’t just some geeky detail. It’s the backbone of AI’s economic future.
FAQ
What does Mixture of Experts mean in simple terms?
Mixture of Experts (MoE) is an AI architecture that divides a big model into smaller specialist sub-networks, or “experts.” A router decides which experts handle parts of the input. Only a few experts activate at a time. Therefore, you get the intelligence of a big model without the huge compute cost.
Is GPT-4 confirmed to use Mixture of Experts?
OpenAI hasn’t officially stated GPT-4’s architecture. But credible reports suggest it uses 8 experts with around 220 billion parameters each. This would give it approximately 1.76 trillion total parameters but only about 220 billion active per inference pass. This matches its observed performance and pricing patterns.
How does MoE reduce AI inference costs?
MoE cuts costs because just a slice of a model’s parameters activate per request. Specifically, if a model holds 1.8 trillion parameters but only 200 billion light up per token, the compute cost looks like that of a 200-billion-parameter dense model. Consequently, providers can offer powerful models more affordably per-token.
Can I run MoE models on my own hardware?
Yes, but with caveats. MoE models need less compute per inference, but the full model must fit in memory. Mixtral 8x7B needs roughly 90 GB of GPU memory in full precision. However, quantized versions can run on consumer hardware with 48 GB or more of VRAM. Plus, frameworks like vLLM and TensorRT-LLM optimize MoE inference for self-hosting.
What’s the difference between MoE and ensemble models?
These are fundamentally different approaches. Ensemble models involve multiple complete, independent models with combined outputs. MoE models train expert sub-networks within a single model, sharing layers with a learned router. MoE is much more parameter-efficient. Furthermore, MoE experts train jointly, while ensemble members are usually trained separately.
Will MoE architecture keep getting more popular?
All signs point to yes. The economics are compelling, hardware is shifting, and both open-source and closed-source labs are investing heavily. Moreover, the mixture of experts explained why biggest AI models use MoE boils down to this: it’s currently the smartest way to scale intelligence without scaling costs in tandem. Until a better approach comes along, MoE will likely remain the dominant frontier architecture.
References
Keep reading
Here are the latest posts from the blog.

Quantization is how AI models get smaller without getting dumber — it’s reshaping machine learning deployment. Ever wondered how a 70-billion-parameter model runs smoothly on…

Sarvam AI closing one of India’s largest private AI funding rounds isn’t just a headline worth skimming past. It’s a seismic shift in how global investors view non-Western AI…

Google just shook up the AI voice game — and I don’t say that lightly. Gemini 3.5 Flash TTS real-time voice synthesis AI represents a genuine leap in how machines produce hum…