
Mechanistic interpretability science looking inside an AI’s brain isn’t just an academic curiosity anymore. It’s become essential — and honestly, it’s overdue.
As AI models grow larger and more powerful, understanding what actually happens inside them matters more than ever. And yet most teams are still flying blind.
Think about it this way. You wouldn’t fly on a plane whose engineers shrugged and said, “We’re not sure why it stays up.” But that’s roughly where we are with modern AI. Models produce remarkable outputs, but we often can’t explain how. Mechanistic interpretability changes that by reverse-engineering the internal computations of neural networks — and I’d argue it’s one of the most important research directions in the field right now.
Furthermore, this discipline connects directly to practical topics you’re probably already wrestling with — quantization, mixture-of-experts architectures, model pruning. Before you compress or scale a model, you need to understand what’s happening inside. Otherwise, you’re just optimizing blindly and hoping for the best.
What Is Mechanistic Interpretability and Why Does It Matter?
Circuit Analysis: Tracing the Wiring Inside Neural Networks
Activation Patterns and Feature Visualization in Modern AI Models
Comparing Interpretability Approaches: Methods, Tools, and Trade-offs
Why Understanding Model Internals Matters Before Compression and Scaling
What Is Mechanistic Interpretability and Why Does It Matter?
Mechanistic interpretability is the practice of understanding neural networks by studying their internal components. Specifically, researchers examine individual neurons, attention heads, and learned circuits. The goal is to build a complete, mechanistic account of how a model transforms inputs into outputs — not just what it does, but why.
This is fundamentally different from traditional interpretability approaches. Older methods treat models as black boxes, observing inputs and outputs and then guessing at relationships. Mechanistic interpretability, by contrast, opens the box entirely. I’ve spent years watching the explainability space evolve, and this shift feels genuinely significant — not just incremental.
Why does this matter? A few reasons stand out:
- Safety: If we can’t understand a model’s reasoning, we can’t guarantee it won’t behave dangerously
- Trust: Regulators and users increasingly demand explanations for AI decisions
- Debugging: Finding and fixing model failures requires understanding internal mechanics
- Alignment: Ensuring AI systems pursue intended goals depends on actually reading their “thought processes”
Notably, organizations like Anthropic have made mechanistic interpretability a core research priority. They argue it’s one of the most promising paths toward safe AI. Meanwhile, independent researchers worldwide are building on that foundation — and the community is growing faster than I expected even two years ago.
The science of looking inside an AI’s brain also has concrete engineering payoffs. Because you can identify which circuits handle specific tasks, you can prune models more intelligently, quantize weights without destroying critical pathways, and remove biases at their source rather than papering over them at the output layer.
Circuit Analysis: Tracing the Wiring Inside Neural Networks
Circuit analysis is the backbone of mechanistic interpretability science looking inside an AI’s brain. It involves identifying specific computational pathways — called circuits — that perform identifiable functions within a model. Think of it like tracing a wire through a complex electrical system until you understand exactly what it powers.
Here’s how circuit analysis actually works. Researchers isolate small subnetworks within larger models, then test whether those subnetworks independently perform specific tasks. A circuit might handle subject-verb agreement, detect sentiment, or recognize named entities. The results are often surprisingly clean — which honestly surprised me the first time I dug into the literature.
The landmark work here came from Chris Olah’s team at Anthropic, who published extensively on transformer circuits. Their research revealed interpretable structures inside models that had seemed completely opaque. It’s the kind of finding that makes you rethink your assumptions about what’s knowable.
Key circuit analysis techniques include:
- Activation patching — Replacing activations at specific points to test causal relationships
- Path patching — Tracing information flow along specific edges in the computational graph
- Ablation studies — Removing components to observe what breaks
- Logit attribution — Measuring each component’s direct contribution to the final output
Additionally, researchers have discovered “induction heads” — attention head pairs that implement in-context learning. These circuits allow models to recognize and continue patterns they’ve never seen during training. This was a groundbreaking discovery, showing that complex behaviors emerge from identifiable, understandable mechanisms. Importantly, it’s reproducible — other teams have confirmed it independently.
Real-world example from GPT-2. Researchers at Redwood Research identified a circuit responsible for indirect object identification. Given the prompt “Mary gave the book to,” the circuit correctly identifies “Mary” as the indirect object. The circuit spans multiple attention heads across several layers. Each head performs a specific sub-task. That level of granularity is what makes circuit analysis so powerful.
Consequently, circuit analysis transforms our understanding of AI from “it just works” to “here’s exactly why it works.” For safety-critical applications, that precision isn’t optional — it’s the whole point.
Activation Patterns and Feature Visualization in Modern AI Models
Beyond circuits, mechanistic interpretability science looking inside an AI’s brain relies heavily on studying activation patterns. Activations are the numerical values neurons produce as data flows through a network. They reveal what features a model has learned to detect — and some of those features are genuinely weird.
The superposition problem. Here’s the real kicker: neural networks represent more features than they have neurons. This phenomenon, called superposition, means individual neurons often respond to multiple unrelated concepts. Therefore, reading individual neurons doesn’t always tell a coherent story. It’s one of the trickier aspects of this work, and it tripped me up early on.
Anthropic’s research on superposition has been particularly influential. Their published findings showed that models compress many features into fewer dimensions using nearly orthogonal directions. Understanding this compression is critical for interpreting model behavior accurately — skip it and your analysis will mislead you.
Sparse autoencoders have emerged as a powerful tool for addressing superposition. These auxiliary networks break down a model’s activations into interpretable features. Specifically, they find directions in activation space that correspond to human-understandable concepts. Fair warning: setting them up correctly has a learning curve, but the payoff is real.
Here’s what researchers have found using these techniques:
- Claude models contain features corresponding to specific concepts like “Golden Gate Bridge,” “deception,” and “code errors”
- GPT-4 shows hierarchical feature organization, with lower layers detecting syntax and higher layers capturing semantics
- Open-source models like Llama and Mistral show similar interpretable structures, suggesting these patterns are universal rather than architecture-specific
Moreover, feature visualization techniques borrowed from computer vision have been adapted for language models. Instead of generating images that maximally activate neurons, researchers generate text sequences that reveal what linguistic patterns each component responds to. It’s a clever adaptation — and the outputs are often illuminating.
Practical implications are significant. Because Anthropic identified a “deception” feature in Claude, they could study when and why it activated. Similarly, identifying features related to harmful content enables more targeted content filtering — not just blocking outputs after the fact, but understanding the internal mechanism that produced them. That’s a meaningful difference.
Comparing Interpretability Approaches: Methods, Tools, and Trade-offs
The field of mechanistic interpretability covers several distinct approaches. Choosing the right one depends on your goals, resources, and the model you’re studying. I’ve worked across a few of these methods, and the honest answer is that each one shows you something different — none of them shows you everything.
| Method | What It Reveals | Computational Cost | Best For | Limitations |
|---|---|---|---|---|
| Circuit analysis | Causal pathways for specific behaviors | High | Safety research, debugging | Doesn’t scale easily to full models |
| Sparse autoencoders | Individual interpretable features | Medium-High | Feature discovery, bias detection | May miss feature interactions |
| Activation patching | Causal role of specific components | Medium | Hypothesis testing | Requires prior hypotheses |
| Probing classifiers | What information is encoded where | Low | Quick exploration | Correlation, not causation |
| Logit lens | Layer-by-layer prediction evolution | Low | Understanding processing stages | Only shows residual stream |
| Attention visualization | Which tokens attend to which | Low | Quick intuition building | Often misleading in isolation |
Nevertheless, no single method tells the complete story. Effective interpretability research combines multiple approaches. For instance, you might use probing classifiers to form hypotheses, then confirm them with activation patching. Quick note: attention visualization in particular looks compelling but is notoriously easy to misread — treat it as a starting point, not a conclusion.
Tools driving the field forward deserve a mention. TransformerLens, developed by Neel Nanda, provides a Python library built specifically for mechanistic interpretability research. It makes hook-based interventions on transformer models genuinely straightforward — I’ve tested a handful of interpretability tools and this one actually delivers on its promise. Additionally, Anthropic’s Neuronpedia offers a searchable database of interpretable features that’s worth bookmarking.
Importantly, the science of looking inside an AI’s brain is becoming more accessible. Two years ago, this work required deep expertise and custom infrastructure. Today, standardized tools and published methods let far more researchers participate. Conversely, the increasing size of frontier models creates new scalability challenges that the community is still working through.
Open-source contributions matter enormously here. Research on models like GPT-2, Pythia, and Llama has produced foundational insights. These smaller, accessible models serve as laboratories where techniques are developed before researchers apply them to larger systems — and that democratization is genuinely exciting.
Why Understanding Model Internals Matters Before Compression and Scaling
Here’s where mechanistic interpretability science looking inside an AI’s brain connects directly to practical AI engineering. If you’ve been following discussions about quantization or mixture-of-experts (MoE) architectures, this section ties everything together. And if you haven’t, it probably should change how you think about both.
The compression connection. Quantization reduces model weights from high-precision to lower-precision numbers, making models smaller and faster. But which weights can you safely compress? Without interpretability, you’re essentially guessing. With circuit analysis, you can identify which weights belong to critical circuits and protect them during quantization — the difference in retained quality can be substantial.
Specifically, research has shown that:
- Critical attention heads lose disproportionate performance when quantized aggressively
- Redundant circuits can be pruned entirely without meaningful quality loss
- Feature directions identified by sparse autoencoders can guide structured pruning decisions
Similarly, MoE architectures route different inputs to different expert subnetworks. Understanding which experts handle which tasks — through mechanistic analysis — enables better routing strategies. It also reveals when experts develop redundant capabilities you didn’t plan for. That kind of insight is hard to get any other way.
The scaling connection. As models grow larger, new capabilities emerge unpredictably. Research published by Google DeepMind has documented these “emergent abilities.” Mechanistic interpretability helps explain why they appear — often, scaling allows circuits that were partially formed to fully crystallize. Furthermore, understanding model internals before scaling helps predict what capabilities the next generation might develop. That’s crucial for safety planning.
A concrete example illustrates this well. Researchers studying arithmetic circuits in language models found that small models use rough heuristics, while larger models develop genuine algorithmic circuits. By understanding this transition mechanistically, engineers can make informed decisions about what model size a specific application actually needs — rather than scaling up by default and hoping for the best.
Consequently, mechanistic interpretability isn’t just theoretical. It directly shapes engineering decisions about compression, scaling, and deployment. Teams that understand their models’ internals make better optimization choices.
The Future of Mechanistic Interpretability Research
The trajectory of mechanistic interpretability science looking inside an AI’s brain points toward several genuinely exciting developments. Although the field is young, its pace of progress is remarkable — and I say that as someone who’s watched plenty of research areas move slowly.
Scaling interpretability to frontier models remains the biggest challenge. Current techniques work well on models with millions or low billions of parameters. Applying them to models with hundreds of billions of parameters requires entirely new approaches. Anthropic’s work on scaling sparse autoencoders to Claude 3 represents early progress here — and it’s worth watching closely.
Automated interpretability is another frontier worth following. Instead of humans manually analyzing circuits, researchers are using AI models to interpret other AI models. OpenAI’s automated interpretability work used GPT-4 to generate explanations for neurons in GPT-2. This meta-approach could dramatically speed up the field — though it also raises interesting questions about how much we should trust an AI’s self-report. That particular irony isn’t lost on anyone in the field.
Key trends to watch include:
- Mechanistic anomaly detection — Using interpretability to flag unusual model behavior in real time
- Interpretability-aware training — Designing training procedures that produce more interpretable models from the start
- Cross-model comparison — Understanding why different architectures develop different internal structures
- Regulatory integration — Governments incorporating interpretability requirements into AI regulations, as explored by NIST’s AI Risk Management Framework
Meanwhile, the research community is growing rapidly. Academic labs, independent researchers, and major AI companies are all investing heavily. Alignment-focused organizations like the Machine Intelligence Research Institute have long advocated for this kind of work — and mainstream research is finally catching up.
Alternatively, some researchers argue that mechanistic interpretability may not scale to the most complex AI behaviors. They suggest certain emergent properties might resist being broken down into understandable circuits. That debate is healthy and ongoing — and honestly, I don’t think anyone has definitively settled it yet.
What’s clear is this: the field has moved from speculative to productive. Real discoveries are being made, safety-relevant insights are emerging, and the tools are improving every month. That trajectory matters.
Conclusion
Mechanistic interpretability science looking inside an AI’s brain has evolved from a niche research interest into a critical discipline. It provides the tools and frameworks needed to understand, trust, and safely deploy AI systems — and notably, it’s starting to shape real engineering decisions, not just academic papers.
The techniques covered here — circuit analysis, activation patching, sparse autoencoders, and feature visualization — form a growing toolkit. Together, they’re turning AI from an inscrutable black box into something we can genuinely reason about. That shift is important, and it’s happening faster than most people realize.
Your actionable next steps:
- Explore TransformerLens — Start experimenting with mechanistic interpretability on small models like GPT-2; the documentation is solid
- Read the transformer circuits thread — Anthropic’s published research provides the best foundation for understanding this field
- Connect interpretability to your work — Whether you’re doing quantization, fine-tuning, or deployment, understanding model internals improves every decision
- Follow key researchers — Neel Nanda, Chris Olah, and the Anthropic interpretability team regularly publish accessible content
- Think about safety implications — Consider how interpretability findings should shape your organization’s AI governance
The science of looking inside an AI’s brain isn’t optional anymore. It’s foundational. As models become more capable and more widely deployed, understanding their internals becomes everyone’s responsibility — not just the safety team’s.
FAQ
What exactly is mechanistic interpretability in simple terms?
Mechanistic interpretability is the practice of reverse-engineering neural networks to understand how they work internally. Think of it like taking apart a clock to see its gears rather than just observing what time it shows. Researchers study individual neurons, attention heads, and circuits to explain why a model produces specific outputs. It goes beyond observing behavior — it explains the underlying mechanisms, which is a meaningfully different thing.
How does mechanistic interpretability differ from traditional explainability methods?
Traditional explainability methods treat models as black boxes, analyzing input-output relationships without examining internals. Techniques like SHAP and LIME fall into this category. Mechanistic interpretability, however, opens the model and studies its components directly. Consequently, it provides causal explanations rather than correlational ones — and that distinction matters significantly for safety applications where “it seems to correlate” isn’t good enough.
Can mechanistic interpretability be applied to any AI model?
In principle, yes. In practice, it’s most developed for transformer-based language models. Specifically, most published research focuses on GPT-2, Pythia, and Anthropic’s Claude models. Applying these techniques to vision models, reinforcement learning agents, or very large frontier models remains challenging. Nevertheless, the fundamental approaches are model-agnostic and increasingly adaptable — the tooling is improving steadily.
Why is mechanistic interpretability important for AI safety?
AI safety requires understanding what models are actually doing, not just what they appear to be doing. Mechanistic interpretability science looking inside an AI’s brain can reveal deceptive behaviors, hidden biases, and failure modes that behavioral testing misses entirely. Moreover, it lets researchers verify that safety training actually changes internal computations rather than just masking surface outputs — an important distinction that behavioral benchmarks alone can’t capture.
What tools do I need to get started with mechanistic interpretability research?
The most accessible starting point is TransformerLens, a Python library built specifically for this purpose. You’ll also need PyTorch and access to open-source models like GPT-2 or Pythia. Additionally, familiarity with linear algebra and transformer architecture is helpful — not optional, honestly, but you can build it alongside the practical work. Anthropic’s published tutorials and Neel Nanda’s video series provide excellent learning resources for beginners.
How does mechanistic interpretability relate to model compression and quantization?
Understanding model internals directly improves compression decisions. Circuit analysis reveals which components are critical and which are redundant. Therefore, engineers can quantize or prune non-essential weights more aggressively while protecting important circuits. This targeted approach to looking inside an AI’s brain produces smaller models that retain more capability than blind compression methods achieve — and in my experience, that gap is larger than most teams expect.
References
Keep reading
Here are the latest posts from the blog.

Three of the most consequential people in tech are about to walk into one of the most politically charged rooms on the planet. Sam Altman, Dario Amodei, and Demis Hassabis at…
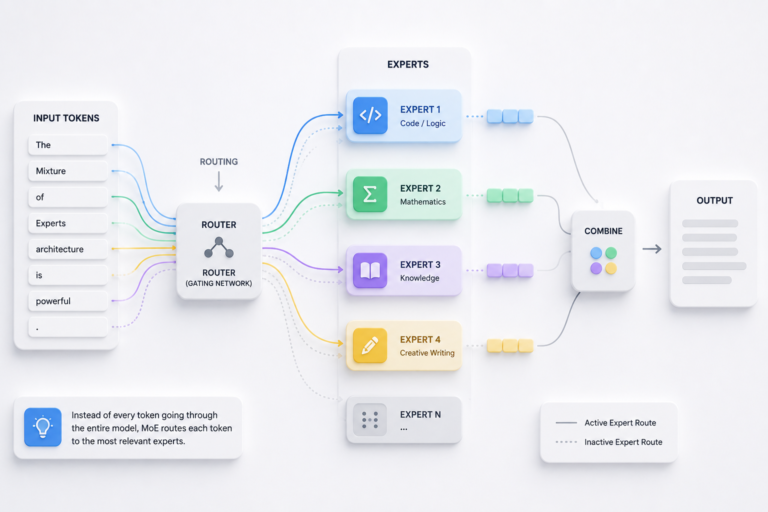
The phrase mixture of experts explained why biggest AI models aren’t monolithic often comes up in AI discussions, and there’s a good reason for that. Today’s leading AI syste…

Quantization is how AI models get smaller without getting dumber — it’s reshaping machine learning deployment. Ever wondered how a 70-billion-parameter model runs smoothly on…