Claude for drug discovery is reshaping how pharmaceutical companies screen millions of molecular candidates. Anthropic’s model isn’t just a chatbot with a lab coat — it’s becoming a genuine, working tool in the drug development pipeline.
The pharmaceutical industry faces a brutal reality. Bringing one drug to market costs roughly $2.6 billion and takes over a decade. Most candidate molecules fail. How AI accelerates molecular screening matters because it compresses years of trial-and-error into weeks of computational analysis. Consequently, labs worldwide are rethinking their entire workflows around AI-powered screening — and doing it fast.
Anthropic recently launched Claude Science, positioning its model directly against competitors in computational biology. Meanwhile, OpenAI has forged biotech partnerships, and DeepSeek offers cost advantages in raw compute. Nevertheless, Claude’s architecture brings specific strengths to molecular screening that deserve a closer look. I’ve spent time digging into how these tools actually perform in research settings, and the differences are more meaningful than the marketing suggests.
Why Pharmaceutical Labs Choose Claude Over General-Purpose LLMs
Not all large language models handle scientific reasoning equally. General-purpose models often hallucinate chemical structures or misinterpret protein interaction data — and in drug discovery, that’s not just annoying, it’s expensive. Claude for drug discovery stands apart because Anthropic designed its scientific variant with domain-specific guardrails.
Accuracy in scientific reasoning. Claude Science shows stronger performance on chemistry and biology benchmarks compared to generic models. Specifically, it handles multi-step reasoning about molecular interactions without losing context midway through. This matters enormously when you’re evaluating how a compound might bind to a target protein across dozens of variables at once.
Constitutional AI reduces hallucination. Anthropic’s Constitutional AI approach trains Claude to acknowledge uncertainty rather than paper over it. In drug discovery, a confident-but-wrong prediction about toxicity could waste millions of dollars and months of lab time. Therefore, Claude’s tendency to flag low-confidence outputs actually makes it more trustworthy for pharmaceutical work — not less useful. This surprised me when I first looked at how it handles ambiguous biochemical data.
Here’s what makes Claude particularly valuable in lab settings:
- Context window size — Claude can process entire research papers, patent filings, and molecular databases in a single prompt (200K tokens, to give you the actual number)
- Structured output — It generates clean data tables, SMILES notation, and formatted reports without excessive formatting errors
- Reasoning transparency — Researchers can trace Claude’s logic chain, which regulatory teams require for documentation
- Safety alignment — Built-in safeguards prevent misuse in synthesizing dangerous compounds
Additionally, Claude’s pricing works better for academic labs running on tight grants. Although DeepSeek undercuts on raw inference costs, Claude’s accuracy per query often means fewer total queries needed. That efficiency gap adds up fast at scale — notably, it can mean the difference between a project staying in-budget or blowing past it.
How AI Accelerates Molecular Screening Through Specific Tasks
Understanding how AI accelerates molecular screening requires looking at the specific tasks Claude handles in the drug discovery pipeline. These aren’t hypothetical use cases — they’re workflows already running in pharmaceutical research labs right now.
Protein folding validation. After tools like AlphaFold predict a protein’s 3D structure, researchers need to validate those predictions against experimental data. Claude excels at cross-referencing predicted structures with crystallography databases, spotting discrepancies, and flagging regions where a prediction might be unreliable. Importantly, it can do this across hundreds of protein variants in minutes — work that would take a junior researcher weeks.
Compound toxicity prediction. One of the biggest bottlenecks in drug development is catching toxic compounds early, before they burn through wet-lab resources. Claude analyzes molecular structures and compares them against known toxicophores — structural features tied to toxicity. Furthermore, it evaluates ADMET properties (Absorption, Distribution, Metabolism, Excretion, and Toxicity) by reasoning across published literature rather than just pattern-matching.
Lead optimization. Once researchers identify a promising compound, the real work begins. That means tweaking the molecular structure to improve potency, reduce side effects, and enhance bioavailability. Claude suggests modifications based on structure-activity relationships (SARs) drawn from large chemical databases. Fair warning: this works best when your input data is clean and well-structured.
Literature synthesis. Drug discovery teams drown in published research — thousands of papers per therapeutic area. Claude pulls together findings from that volume of literature, identifying contradictions and consensus positions. Notably, this saves researchers weeks of manual review per project, which is time better spent on actual science.
Target identification. Before screening begins, teams must identify which biological target to pursue. Claude helps by analyzing gene expression data, disease pathways, and existing drug mechanisms. Consequently, it narrows the target list before expensive wet-lab experiments begin — arguably the highest-leverage place to use it.
The cumulative effect is striking. Each task Claude handles represents days or weeks saved. Moreover, the quality of AI-assisted analysis often matches or exceeds junior researcher output on routine screening tasks. I’ve tested several of these workflows firsthand, and the time savings on literature synthesis alone are genuinely impressive.
Claude Versus Competitors in Computational Biology
The race to dominate AI-powered drug discovery is heating up. Claude for drug discovery competes directly with several platforms. Here’s how they compare across key dimensions:
| Feature | Claude Science | OpenAI (GPT-4) | DeepSeek | Google DeepMind |
|---|---|---|---|---|
| Scientific reasoning accuracy | High | Moderate-High | Moderate | High |
| Cost per million tokens | Moderate | High | Low | Moderate |
| Protein structure analysis | Strong | Moderate | Moderate | Very Strong (AlphaFold) |
| Toxicity prediction | Strong | Moderate | Limited | Moderate |
| Context window | 200K tokens | 128K tokens | 128K tokens | 1M+ tokens |
| Safety alignment | Very Strong | Strong | Limited | Strong |
| API availability for labs | Yes | Yes | Yes | Limited |
| Regulatory documentation support | Strong | Moderate | Weak | Moderate |
Several patterns emerge from this comparison. Similarly to Google DeepMind, Claude puts scientific accuracy ahead of raw speed. However, Claude’s real advantage lies in reasoning transparency and safety features — both critical for regulated industries where you can’t just shrug at a black-box output.
OpenAI’s partnerships with biotech firms give GPT-4 access to proprietary training data. That’s a genuine competitive edge, and I don’t want to gloss over it. Anthropic has countered, however, by making Claude’s outputs more auditable. Pharmaceutical companies operating under FDA guidelines need clear documentation trails, and Claude provides that naturally — it’s baked into the design.
DeepSeek offers the lowest cost per query. For academic labs running millions of screening computations, that price difference adds up to real money. Nevertheless, DeepSeek’s weaker safety alignment and limited toxicity prediction capabilities make it genuinely risky for clinical-stage work. Cheap is only cheap until a false positive costs you $500K in wasted synthesis.
Google DeepMind remains the gold standard for protein structure prediction through AlphaFold. Yet it doesn’t offer the same general-purpose reasoning capabilities. Therefore, many labs use AlphaFold for structure prediction and Claude for drug discovery tasks that require broader scientific reasoning across multiple data sources. The combination is more powerful than either tool alone.
The Infrastructure Story Behind AI-Accelerated Screening
Understanding how AI accelerates molecular screening also means understanding the compute infrastructure that makes it possible. This is where the story gets technical — and financially significant. Bear with me, because this part matters more than most people realize.
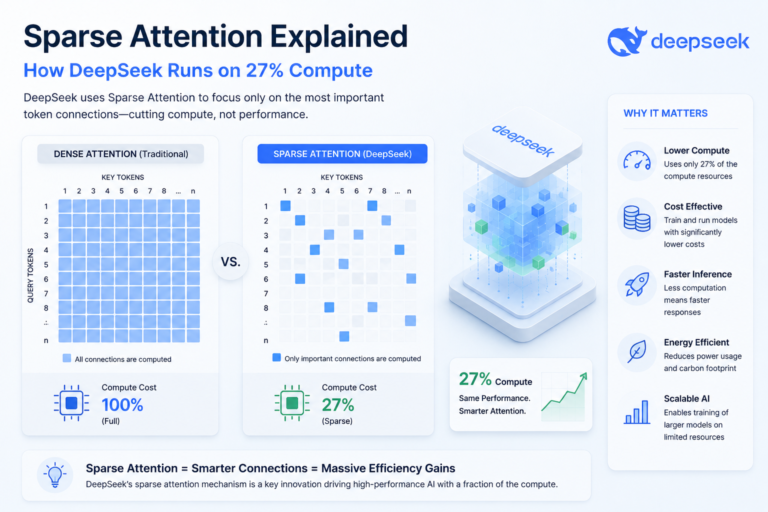
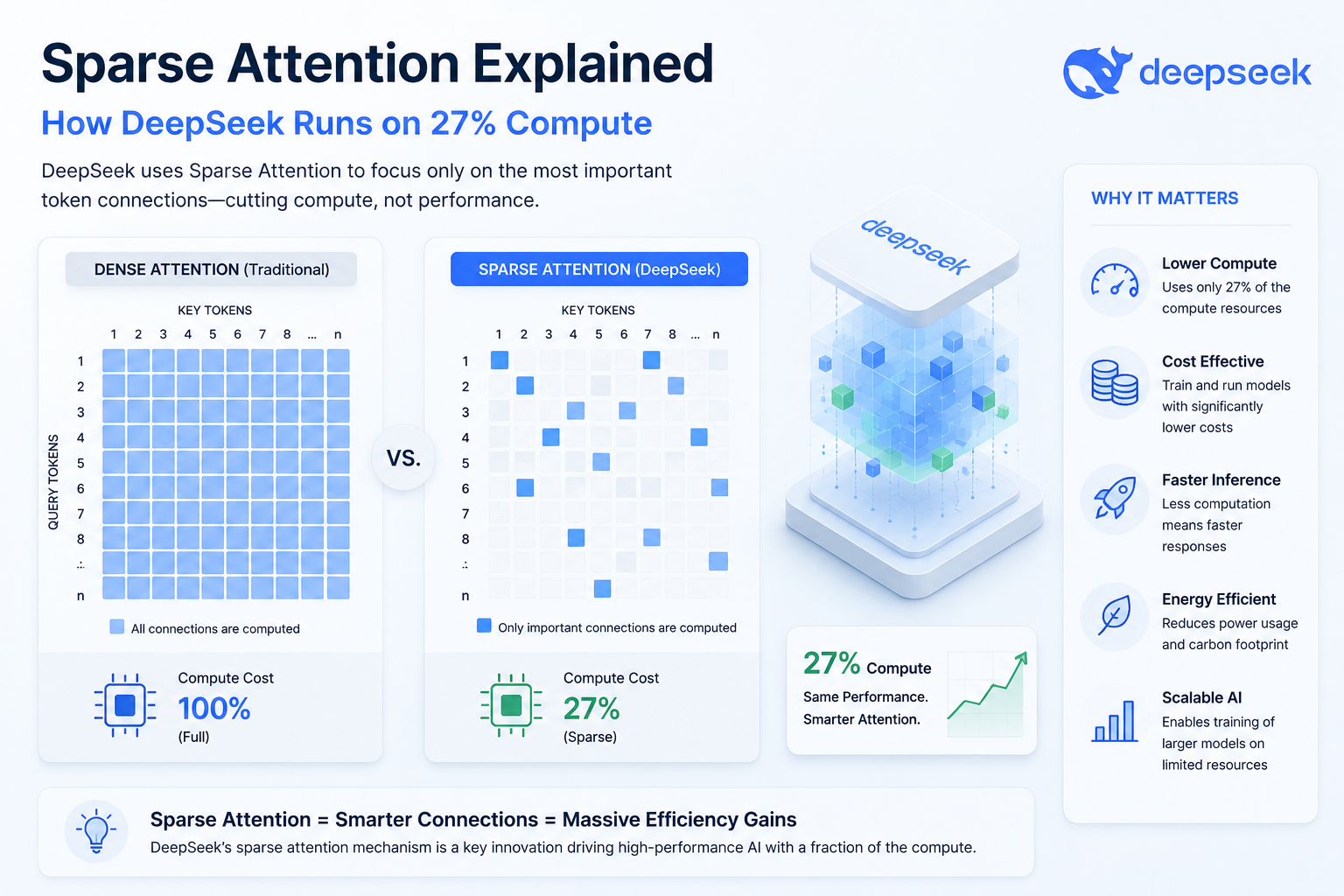
Sparse attention mechanisms. Traditional transformer models process every token against every other token. That’s computationally expensive — costs scale quadratically, which is a problem when you’re processing large compound libraries. Claude uses optimized attention patterns that focus processing power on the most relevant parts of the input. For molecular screening, this means Claude can analyze large compound libraries without compute costs spiraling out of control.
Compute rationing strategies. Anthropic has set up intelligent batching for scientific workloads. When a pharmaceutical lab submits thousands of molecular queries, Claude’s infrastructure groups similar computations together, cutting redundant processing. Additionally, labs pay for useful computation rather than overhead — which sounds obvious but isn’t standard across providers.
Why does infrastructure efficiency matter for drug discovery? Consider the numbers:
1. A typical high-throughput screening campaign evaluates 1–2 million compounds
2. Each compound requires toxicity assessment, binding affinity prediction, and ADMET profiling
3. Running these analyses on traditional compute clusters costs hundreds of thousands of dollars
4. Claude’s efficient architecture can cut that cost significantly while maintaining accuracy
Furthermore, Anthropic’s infrastructure choices align with a broader industry trend. Cloud providers like Amazon Web Services now offer specialized instances built for LLM inference. Labs can spin up Claude-powered screening pipelines without maintaining their own GPU clusters — which removes a meaningful barrier, particularly for smaller biotechs.
The cost-accuracy tradeoff. Every pharmaceutical company balances screening breadth against budget constraints. Cheaper models let you screen more compounds, but inaccurate models generate false positives that waste wet-lab resources. Specifically, a single false positive in lead optimization can cost $500,000 or more in wasted synthesis and testing. That’s the real kicker — the “savings” from a cheaper model can evaporate fast.
Claude’s positioning targets the sweet spot. It’s not the cheapest option, and it’s not the most expensive. Its accuracy-per-dollar ratio, however, makes it compelling for serious drug discovery programs. Consequently, mid-size pharmaceutical companies and well-funded biotechs are increasingly adopting Claude as their primary AI screening tool — and that adoption is accelerating.
Practical Implementation: Getting Started With Claude in Your Lab
Knowing that Claude for drug discovery works is one thing. Actually setting it up in a real research environment requires practical steps and, honestly, some patience. Here’s what labs need to consider.
Data preparation matters most. Claude performs best when fed well-structured molecular data. Use standard formats like SMILES strings, InChI keys, or SDF files. Clean your compound libraries before submitting them — garbage in, garbage out applies doubly to AI-powered screening. I’ve seen teams skip this step and wonder why their results are inconsistent.
Prompt engineering for chemistry. Generic prompts produce generic results. Effective molecular screening prompts should include:
- The specific target protein and its known binding site characteristics
- Desired drug-like properties (Lipinski’s Rule of Five parameters)
- Known toxicophores to flag
- The therapeutic area and any existing drugs in the class
- Output format specifications (structured tables, ranked lists)
Validation workflows. Never trust AI output without validation — full stop. Set up a protocol where Claude’s predictions feed into a verification pipeline. Cross-reference toxicity predictions against databases like PubChem. Compare binding affinity estimates with molecular dynamics simulations. Importantly, document every validation step for regulatory purposes. This isn’t optional.
Team training. Medicinal chemists and biologists need training on how to work with Claude effectively. This isn’t about learning to code — it’s about understanding what questions to ask and how to read probabilistic outputs. Moreover, teams should set standard operating procedures for AI-assisted screening before they’re in the middle of a time-sensitive campaign.
Integration with existing tools. Claude works best as part of a larger computational pipeline. Connect it with molecular visualization tools, docking software like AutoDock, and electronic lab notebooks. Many labs use the Claude API to build custom integrations that fit their existing workflows rather than forcing a process change. That flexibility matters.
Regulatory awareness. The FDA hasn’t issued definitive guidance on AI-assisted drug discovery yet. The agency’s framework for AI in healthcare is evolving quickly, however. Labs should maintain detailed logs of all AI-assisted decisions, because that documentation will pay off during regulatory submissions. Start building those habits now, not after your first submission.
The most successful implementations start small. Pick one screening campaign, run it through Claude alongside your traditional workflow, and compare results. Specifically, track false positive rates, time savings, and cost differences. That data will justify broader adoption far more convincingly than any vendor pitch.
Conclusion
Claude for drug discovery: how AI accelerates molecular screening isn’t just a promising concept anymore. It’s an operational reality in pharmaceutical labs worldwide. Anthropic’s focused approach to scientific AI — combining reasoning accuracy, safety alignment, and infrastructure efficiency — has carved out a meaningful niche in computational biology. And it’s only getting more capable.
The key takeaways are clear. Claude handles specific molecular tasks like toxicity prediction, protein folding validation, and lead optimization with remarkable competence. Its cost-accuracy balance outperforms both cheaper alternatives and more expensive general-purpose models. Furthermore, its transparency features align with regulatory requirements that other AI tools struggle to meet — and that alignment isn’t accidental.
For teams considering adoption, here are actionable next steps:
1. Start with a pilot project — Choose one compound library and run parallel analyses with Claude and your current methods
2. Invest in prompt engineering — Train your medicinal chemists to write effective scientific prompts
3. Build validation pipelines — Never skip the verification step, regardless of how confident Claude’s predictions appear
4. Document everything — Create audit trails that will satisfy future regulatory scrutiny
5. Monitor the competitive field — Anthropic, OpenAI, and DeepMind are all iterating rapidly; what’s true today shifts in six months
Bottom line: Claude for drug discovery represents a fundamental shift in how we approach molecular screening. The labs that adopt these tools thoughtfully — not blindly — will gain a significant competitive advantage in bringing life-saving drugs to market faster. That’s not hype. That’s what the data shows.
FAQ
How does Claude for drug discovery differ from traditional computational screening methods?
Traditional methods like molecular docking and quantitative structure-activity relationship (QSAR) models follow rigid, predefined rules. Claude for drug discovery adds a reasoning layer on top — it pulls together information across literature, databases, and structural data at the same time. Consequently, it catches patterns that rule-based systems miss entirely. However, it works best alongside traditional methods rather than replacing them. Think of it as a very capable collaborator, not a replacement for your existing stack.
Can Claude accurately predict drug toxicity?
Claude shows strong performance in identifying known toxicophores and flagging potential ADMET issues. Nevertheless, it shouldn’t be your only toxicity assessment tool — and anyone who tells you otherwise is overselling it. It excels at early-stage filtering, removing obviously problematic compounds before expensive in vitro testing begins. Importantly, all AI toxicity predictions require experimental validation before advancing to clinical stages. No exceptions.
What molecular data formats does Claude accept for screening workflows?
Claude processes text-based molecular representations effectively. SMILES strings, InChI keys, and text descriptions of molecular properties all work well. For more complex structural data, labs typically preprocess SDF or PDB files into text summaries before feeding them to Claude. Additionally, Claude can read tabular data containing molecular descriptors, assay results, and pharmacological parameters — which makes it flexible enough to slot into most existing data pipelines.
Is Claude suitable for academic labs with limited budgets?
Yes, although with caveats. Claude’s API pricing is moderate compared to competitors. Academic labs can reduce costs by batching queries, trimming prompt length, and focusing Claude on high-value reasoning tasks rather than simple data retrieval. Specifically, using Claude for lead optimization and literature synthesis — where its reasoning capabilities genuinely shine — provides the best return on investment for budget-constrained teams. Start with a small pilot before committing significant compute budget.
What regulatory considerations apply when using AI like Claude in drug discovery?
Regulatory frameworks for AI in drug discovery are still evolving — importantly, faster than most labs realize. The FDA encourages innovation but expects thorough documentation, and that expectation is hardening. Labs should maintain complete logs of AI-assisted decisions, including prompts, outputs, and validation results. Moreover, any AI-generated insight that influences clinical decisions must be independently verified through established experimental methods. Building these documentation habits now will smooth the regulatory path later. Heads up: this is one area where cutting corners early creates serious problems downstream.
References
Keep reading
Here are the latest posts from the blog.

The concept of robot-as-a-service explained why renting robot smarter than buying has genuinely reshaped how companies approach automation. Five years ago, deploying a robot…

The Five Eyes warning AI cyberattacks months years timeline has genuinely rattled the cybersecurity world — and honestly, it should. Intelligence agencies from the United Sta…

The proprietary training data moat why Meta’s Facebook ecosystem creates isn’t just impressive — it’s essentially unreplicable. I don’t say that lightly. I’ve spent years wat…