
Here’s the thing: why China training a trillion-parameter model on domestic chips matters isn’t really about AI benchmarks. It’s about the entire foundation of Washington’s semiconductor strategy cracking under pressure — and nobody in the policy world seems quite ready to admit it.
In early 2025, Chinese AI lab DeepSeek stunned pretty much everyone by training massive models that rival GPT-4 performance — without latest-generation NVIDIA hardware. That wasn’t supposed to happen. U.S. export controls were designed specifically to prevent it. Nevertheless, Chinese engineers found workarounds that caught Washington completely flat-footed.
The implications stretch far beyond AI leaderboards. We’re talking national security, trade policy, and the long-term future of American semiconductor dominance. So let’s get into exactly how this happened, what it actually means, and where things go from here.
How Chinese Labs Train Trillion-Parameter Models on Domestic Chips
The Export Control Calculus Before and After Domestic Chip Breakthroughs
Vertical Integration: China’s Semiconductor Self-Sufficiency Strategy
Cost Comparisons and Training Timelines: Domestic vs. NVIDIA-Dependent Approaches
How Chinese Labs Train Trillion-Parameter Models on Domestic Chips
The question of why China training trillion-parameter model domestic hardware works at all starts with clever engineering — not magic, not theft, just clever engineering. Specifically, three interconnected strategies: chip design, software optimization, and architectural innovation.
Huawei’s Ascend 910B and 910C processors sit at the center of this effort. These chips don’t match NVIDIA’s H100 in raw performance — and I want to be honest about that gap rather than paper over it. However, Chinese engineers have compensated through sheer scale and software tricks that are, frankly, impressive. The Ascend 910B delivers roughly 256 TOPS (tera operations per second) of INT8 performance — approximately half the H100’s throughput. When you cluster thousands of them together with optimized interconnects, though, the gap narrows considerably.
DeepSeek’s approach involves several key innovations:
- Mixture of Experts (MoE) architecture — only a fraction of parameters activate per token, which meaningfully reduces compute needs without gutting model quality
- Multi-head latent attention — compresses key-value caches to slash memory requirements
- FP8 mixed-precision training — lowers the precision of calculations without sacrificing model quality
- Custom communication libraries — optimize data transfer between domestic chips
Moreover, the DeepSeek-V3 technical report revealed something that genuinely surprised me when I first read it. The team trained their 671-billion-parameter MoE model using just 2,048 NVIDIA H800 GPUs — a fraction of what Meta used for Llama 3. Total compute cost: approximately $5.6 million, compared to hundreds of millions for comparable Western models.
Now imagine applying those same efficiency techniques to domestic Ascend chips. That’s precisely what’s happening. Although Ascend hardware is less powerful per chip, the efficiency playbook makes trillion-parameter training feasible. Consequently, the entire premise of export controls — that China can’t train frontier models without American chips — is crumbling faster than most people expected.
The Export Control Calculus Before and After Domestic Chip Breakthroughs
Washington’s semiconductor strategy rested on a simple theory: deny China access to advanced chips, and you deny them advanced AI. The Bureau of Industry and Security (BIS) set up increasingly strict controls starting in October 2022, targeting chips above certain compute thresholds and restricting chip-making equipment from ASML, Applied Materials, and others.
I’ve followed export control policy for years, and the logic always seemed cleaner on paper than in practice.
Before domestic breakthroughs, the calculus looked straightforward:
1. China needed NVIDIA A100/H100 GPUs for frontier training
2. Export controls blocked legal access to these chips
3. Smuggling couldn’t provide the thousands of chips needed at scale
4. Therefore, China’s AI progress would slow significantly
After domestic breakthroughs, the calculus has inverted:
1. Chinese labs showed frontier-level results with weaker hardware
2. Domestic chip production is scaling rapidly
3. Software efficiency compensates for hardware gaps
4. Therefore, export controls primarily hurt American chip companies’ revenue
This shift is the real kicker — and it explains why China training trillion-parameter model domestic capabilities matters so much strategically. Furthermore, it creates a genuine paradox for U.S. policymakers. Tighter restrictions actually accelerate China’s push toward self-sufficiency. Meanwhile, American companies like NVIDIA lose access to their second-largest market. That’s not a win by any reasonable definition.
The numbers tell the story clearly. NVIDIA reported that China accounted for roughly 17% of its revenue before restrictions hit. After the October 2022 controls, the company created downgraded chips (A800, H800) specifically for the Chinese market — then Washington restricted those too. Consequently, NVIDIA’s China revenue dropped, but Chinese AI capabilities didn’t. That asymmetry should bother everyone involved.
| Factor | Pre-Domestic Chips (2022) | Post-Domestic Chips (2025) |
|---|---|---|
| Primary training hardware | NVIDIA A100/H100 | Huawei Ascend 910B/910C + stockpiled NVIDIA |
| Estimated cost per trillion-parameter run | $300M–$500M | $50M–$150M (with efficiency techniques) |
| Chip supply vulnerability | High (dependent on imports) | Medium (domestic production scaling) |
| Software ecosystem maturity | Low (CUDA-dependent) | Medium (MindSpore, custom frameworks) |
| Export control effectiveness | High | Low and declining |
| U.S. leverage over China’s AI timeline | Strong | Weak |
Vertical Integration: China’s Semiconductor Self-Sufficiency Strategy
Understanding why China training trillion-parameter model domestic hardware succeeds also requires zooming out to look at the broader industrial strategy. China isn’t just building chips — it’s building an entire semiconductor ecosystem from scratch, layer by layer.
SMIC (Semiconductor Manufacturing International Corporation) now produces chips at 7nm process nodes, two to three generations behind TSMC’s cutting edge. Nevertheless, that’s sufficient for AI training chips — and that distinction matters enormously. The SMIC N+2 process reportedly powers Huawei’s latest Kirin and Ascend processors. Additionally, China has invested over $150 billion in semiconductor subsidies through its “Big Fund” initiatives. That’s not a rounding error.
The vertical integration strategy covers every layer:
- Design — Huawei HiSilicon, Cambricon, Biren Technology
- Manufacturing — SMIC, Hua Hong Semiconductor
- Packaging — Advanced packaging facilities across Jiangsu and Shanghai
- Software — Huawei MindSpore framework, custom CUDA alternatives
- Interconnects — Domestic high-bandwidth networking solutions
- Memory — CXMT (ChangXin Memory Technologies) for DRAM production
Importantly, this isn’t happening in isolation. The Chinese government treats semiconductor self-sufficiency as a national priority on par with its space program — and if you’ve watched how seriously they pursue space, that comparison should give you pause. Specifically, the “Made in China 2025” initiative explicitly targets chip independence, and recent geopolitical tensions have only intensified that drive.
The software layer deserves special attention. NVIDIA’s dominance isn’t just about hardware — it’s about CUDA, the software ecosystem that makes GPU programming accessible. Every major AI framework — PyTorch, TensorFlow, JAX — runs optimized for CUDA. Breaking free from CUDA is arguably harder than building competitive chips, and I don’t think enough people appreciate that.
Nevertheless, Chinese labs are making real progress here. Huawei’s MindSpore framework now supports large-scale training on Ascend hardware. DeepSeek has developed custom kernels that optimize training on non-NVIDIA hardware. Similarly, Alibaba’s PAI platform supports domestic chip training. The ecosystem is immature compared to CUDA — no point pretending otherwise — but it’s functional and improving rapidly.
This vertical integration explains a key dimension of why China training trillion-parameter model domestic chips reshapes the strategic picture. Even if export controls tighten further, China’s dependency on American technology decreases with each passing quarter. And that trajectory doesn’t reverse easily.
Cost Comparisons and Training Timelines: Domestic vs. NVIDIA-Dependent Approaches
One of the most compelling aspects of why China training trillion-parameter model domestic hardware matters is the cost equation. Conventional wisdom held that training on weaker chips would be too expensive to bother with. The reality is more nuanced — and honestly more interesting.
Training timeline comparisons show some surprising dynamics. A trillion-parameter model on 16,000 NVIDIA H100 GPUs might take 90 days. The same model on 32,000 Ascend 910B chips could take 150–180 days. Slower, certainly — but not impossible, and the timeline gap is shrinking with each software optimization cycle.
Moreover, Chinese labs have found that algorithmic efficiency can offset hardware disadvantages in ways that weren’t obvious two years ago. DeepSeek’s sparse attention mechanisms cut compute requirements by 40–60% for certain operations. Their mixture-of-experts approach means only 37 billion parameters activate per forward pass in a 671-billion-parameter model. Consequently, the effective compute requirement drops dramatically — and that changes everything about the cost math.
Cost breakdown for a hypothetical trillion-parameter training run:
| Cost Component | NVIDIA H100 Cluster (U.S.) | Ascend 910B Cluster (China) |
|---|---|---|
| Hardware procurement | $400M (16,000 GPUs at $25K each) | $200M–$280M (32,000 chips, subsidized pricing) |
| Power consumption (90–180 days) | $15M–$20M | $20M–$35M |
| Cooling and infrastructure | $10M–$15M | $12M–$18M |
| Engineering team (12 months) | $20M–$30M | $8M–$15M |
| Software licensing | $5M–$10M | Minimal (open-source stack) |
| Total estimated cost | $450M–$475M | $240M–$348M |
These figures are approximate — treat them as directional, not definitive. But they make an important point. Although domestic chips are individually weaker, the total cost of ownership can actually be lower. Chinese engineering talent costs less, government subsidies cut hardware costs, and open-source software removes licensing fees. I’ve seen people dismiss this argument, and I think that’s a mistake.
Additionally, electricity costs in China’s western provinces run well below U.S. data center rates. Inner Mongolia and Guizhou province host massive data centers with power costs around $0.04–$0.06 per kWh, compared to $0.08–$0.12 per kWh in major U.S. data center markets. Over a multi-month training run consuming hundreds of megawatts, those differences compound substantially — we’re talking tens of millions of dollars in savings.
Therefore, the cost argument for export controls weakens further. Chinese labs aren’t just finding ways to train on domestic chips — they’re potentially doing it cheaper than their American counterparts. This reality fundamentally changes the strategic calculus around why China training trillion-parameter model domestic capabilities should concern U.S. policymakers.
What This Means for U.S. Policy and the Global AI Race
The strategic implications of why China training trillion-parameter model domestic hardware works extend far beyond the semiconductor industry. They force a complete rethink of how technology competition actually works in practice.
For U.S. policymakers, several uncomfortable truths emerge:
1. Export controls have a shelf life. They buy time but don’t prevent capability development. Specifically, they may speed up domestic alternatives — which is the opposite of the intended effect.
2. Revenue loss weakens American companies. NVIDIA, AMD, and Intel lose billions in potential China sales — that’s less money for R&D. And R&D is where the long-term lead gets built or lost.
3. Allied coordination is fragile. The Netherlands and Japan have set up complementary export restrictions, but enforcement gaps persist across multiple jurisdictions.
4. The efficiency gap is closing. Chinese labs are publishing papers showing they need less compute per capability gain — and those papers are freely available to everyone.
Notably, some analysts argue the U.S. should shift from denial strategies to acceleration strategies. Instead of trying to slow China down, focus on running faster. Invest more in domestic AI research, simplify immigration for AI talent, and fund next-generation chip designs that maintain a wider performance gap. That argument is gaining traction, and I find it increasingly persuasive.
For the global AI ecosystem, the implications are equally significant. A world with two separate AI technology stacks — one American, one Chinese — creates fragmentation that nobody really wants. Standards diverge, interoperability suffers, and countries must choose sides.
Meanwhile, other nations are watching closely. India, Saudi Arabia, and the UAE are all investing in AI infrastructure and learning from China’s playbook. Specifically, they’re exploring how to cut dependency on any single chip supplier. Consequently, NVIDIA’s global dominance faces pressure from multiple directions at once — not just from Beijing.
The open-source dimension adds another layer worth considering. DeepSeek released its model weights publicly, which means anyone can study and copy their efficiency techniques. Furthermore, it shows that frontier AI capabilities don’t require frontier hardware — a message that resonates powerfully with resource-limited nations trying to build their own AI capabilities.
Alternatively, some experts suggest a more collaborative approach. Rather than technological containment, pursue AI safety agreements that address shared risks. The OECD AI Policy Observatory has frameworks for international AI governance, though geopolitical tensions make meaningful cooperation increasingly difficult right now.
Bottom line: the question of why China training trillion-parameter model domestic chips changes everything isn’t hypothetical anymore. It’s happening now, and the policy response hasn’t caught up.
Conclusion
The evidence is clear — and I say that as someone who spent years being cautiously skeptical of these claims. Why China training trillion-parameter model domestic chips changes the export control calculus comes down to three factors: engineering ingenuity, vertical integration, and algorithmic efficiency. Together, they’ve knocked out the core assumption behind U.S. semiconductor restrictions.
Chinese labs like DeepSeek have proven that frontier AI doesn’t require frontier hardware. Huawei’s Ascend chips, combined with smart software optimization, can support trillion-parameter training runs. The costs are competitive, the timelines are manageable, and the domestic ecosystem grows stronger every quarter.
Actionable takeaways for technology professionals and policymakers:
- Track domestic chip progress closely. Monitor Huawei Ascend roadmaps and SMIC manufacturing capabilities quarterly — the pace of change is faster than most forecasts suggest.
- Study efficiency techniques. MoE architectures, sparse attention, and FP8 training aren’t just Chinese innovations — they’re universally applicable and worth understanding deeply.
- Reassess supply chain assumptions. Any strategy built on permanent hardware denial needs updating, probably urgently.
- Invest in acceleration, not just denial. The U.S. maintains a lead, but that lead requires active investment to preserve — it won’t hold on its own.
- Prepare for a split ecosystem. Two separate AI technology stacks may become the new normal, and planning for that scenario is no longer paranoid.
Understanding why China training trillion-parameter model domestic hardware works isn’t just an academic exercise. For anyone making strategic decisions about AI, semiconductors, or national security in the years ahead, it’s essential knowledge — and the learning curve is real.
FAQ
How is China training trillion-parameter models without NVIDIA chips?
Chinese labs use a combination of domestic Huawei Ascend processors and algorithmic efficiency techniques. Specifically, approaches like mixture-of-experts architectures cut the compute needed per training step. FP8 mixed-precision training and sparse attention mechanisms further lower hardware requirements. Additionally, labs like DeepSeek have developed custom software kernels optimized for non-NVIDIA hardware. The result is that individually weaker chips, deployed at scale with smart software, can handle trillion-parameter workloads — which wasn’t supposed to be possible this soon.
What are the specs of Huawei’s Ascend 910B compared to NVIDIA’s H100?
The Ascend 910B delivers approximately 256 TOPS of INT8 performance, compared to the H100’s roughly 4,000 TOPS (with sparsity). However, direct comparisons are misleading. The Ascend chips cost less, and Chinese labs compensate by using larger clusters. Furthermore, the upcoming Ascend 910C reportedly narrows the performance gap considerably. The biggest remaining disadvantage isn’t raw compute — it’s the software ecosystem maturity around CUDA, and that gap is harder to close than the hardware gap.
Why don’t U.S. export controls stop China’s AI progress?
Export controls were designed to create a hardware bottleneck. Nevertheless, they didn’t account for three developments that, in hindsight, seem fairly predictable. First, China stockpiled significant quantities of restricted chips before controls took effect. Second, domestic chip production advanced faster than expected. Third, algorithmic breakthroughs cut the amount of compute needed. Consequently, controls have slowed progress but haven’t stopped it. Moreover, they’ve pushed China to invest even more heavily in semiconductor self-sufficiency — which is arguably the worst possible outcome for U.S. long-term strategy.
How much does it cost China to train a trillion-parameter model domestically?
Estimates range from $240 million to $350 million for a full training run on domestic hardware. That’s potentially cheaper than equivalent NVIDIA-based runs in the U.S., which can exceed $450 million. Lower engineering costs, government subsidies, and cheap electricity in China’s western provinces all contribute meaningfully. Importantly, efficiency techniques like those pioneered by DeepSeek could push costs even lower in future training runs — and that trajectory only goes one direction.
What is the mixture-of-experts architecture and why does it matter for domestic chip training?
Mixture of experts (MoE) is a model architecture where only a subset of parameters activates for each input. A 671-billion-parameter MoE model might only use 37 billion parameters per forward pass, which cuts the compute required per step. For domestic chip training, MoE is important because it lets trillion-parameter models run on hardware that couldn’t handle dense models of the same size. It’s essentially a way to get big-model performance with small-model compute budgets — and that’s a clear advantage when your hardware is already behind.
Will China eventually match NVIDIA’s chip performance?
Complete parity is unlikely in the near term — TSMC’s advanced manufacturing processes (3nm, 2nm) give NVIDIA a significant hardware advantage that doesn’t disappear overnight. However, the relevant question isn’t whether China matches NVIDIA chip-for-chip. It’s whether Chinese chips become “good enough” for frontier AI training. Given current trends in algorithmic efficiency and domestic manufacturing progress, the answer is increasingly yes. Furthermore, each generation of Ascend chips closes the gap. Within three to five years, the performance difference may become strategically irrelevant for most AI training workloads — and that’s the timeline policymakers should be planning around.
References
Keep reading
Here are the latest posts from the blog.

Microsoft just made one of the boldest energy bets in tech history. The first major project is Kilby, a 2.67-gigawatt gas-fired plant in West Texas — built specifically to po…
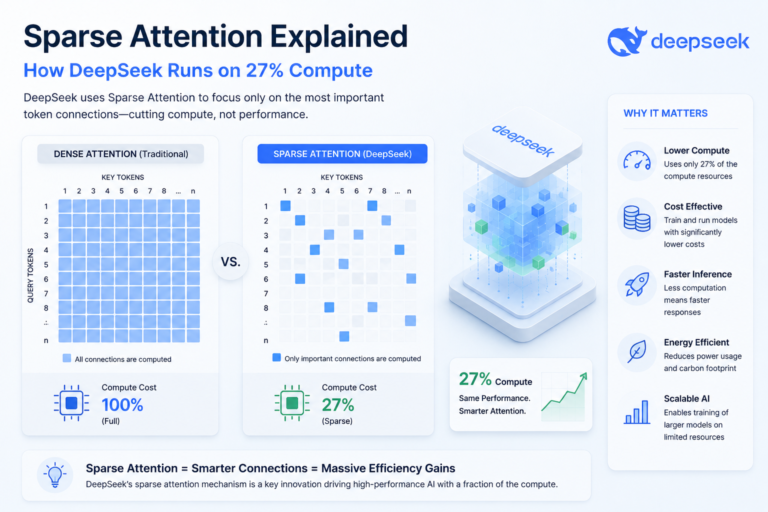
When sparse attention explained how DeepSeek runs trillion-parameter models hit the AI community, jaws dropped. A model that massive should demand enormous compute. Yet DeepS…

Amazon Web Services just made its boldest move yet. AWS launches $1B AI deployment unit engineers directly into customer operations, fundamentally changing how enterprises ad…