The Langflow LLM application attack surface — why building with visual AI frameworks matters — is something most security teams are dangerously underprepared for. And I mean dangerously. These drag-and-drop orchestration tools make building AI apps fast, sometimes impressively so. However, speed comes with hidden costs that don’t show up until something goes wrong.
Specifically, frameworks like Langflow introduce attack vectors that simply don’t exist when you call a Large Language Model (LLM) API directly. They stack layers of abstraction on top of each other, and each layer is a potential entry point for attackers. The visual simplicity that makes these tools so appealing? That’s exactly what makes their risks so easy to miss.
This piece breaks down the concrete vulnerabilities, compares framework-based risks to direct API approaches, and gives you mitigation patterns you can actually set up today — not theoretical stuff, real controls.
How Visual AI Builders Expand the Langflow LLM Application Attack Surface
Prompt Injection Attacks Specific to Orchestration Frameworks
Why Building With Frameworks Accelerates Attacker Capabilities
Comparing Attack Surfaces: Direct API vs. Framework-Based LLM Applications
Mitigation Patterns for the Langflow LLM Application Attack Surface
How Visual AI Builders Expand the Langflow LLM Application Attack Surface
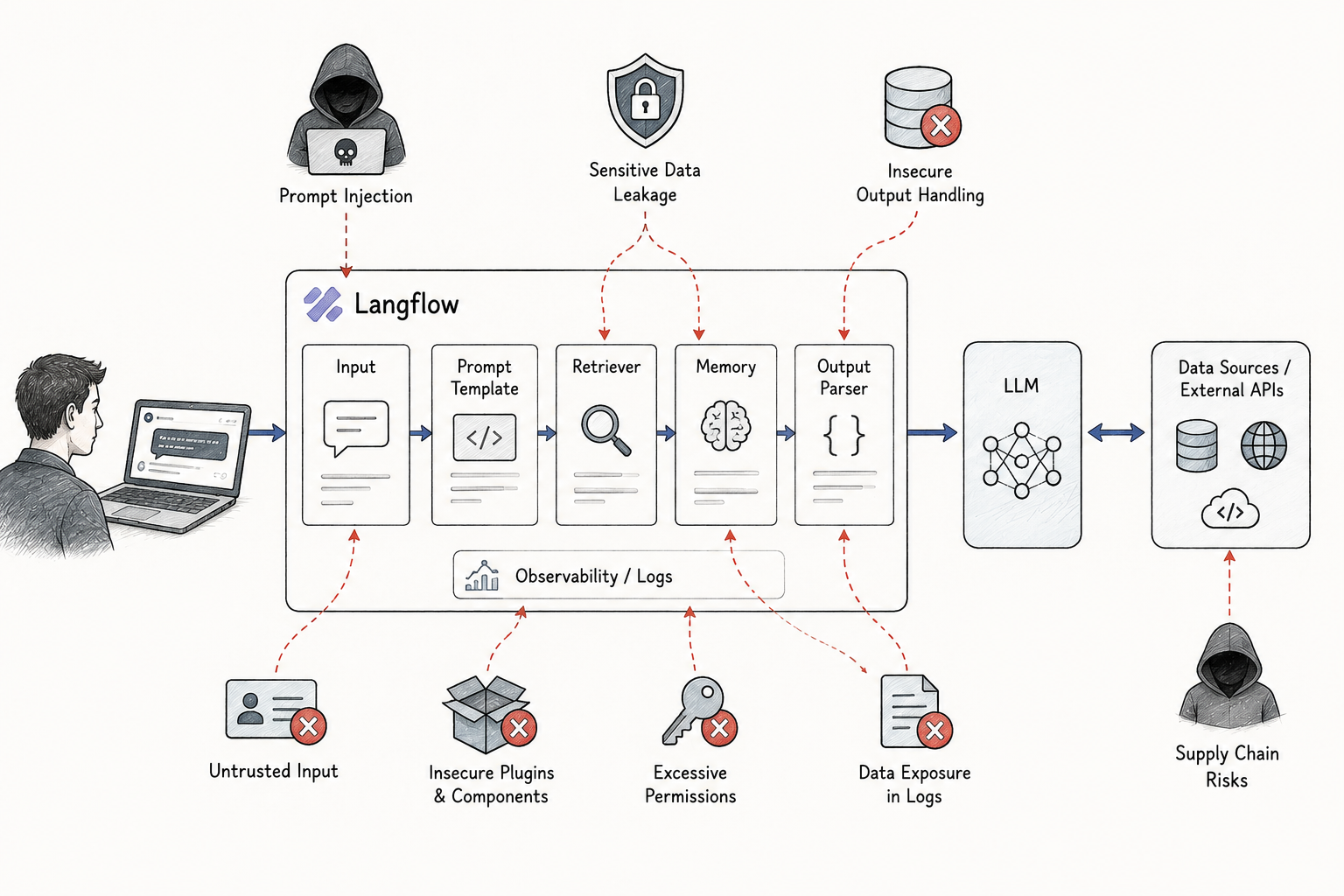
Understanding why building with orchestration frameworks changes your risk profile starts with architecture. When you call an LLM API directly, your attack surface is relatively narrow — you control authentication, input validation, and output handling inside your own codebase. However, the moment you introduce a framework like Langflow, you inherit an entirely new stack of components you didn’t write and probably haven’t audited.
I’ve reviewed deployments at several mid-sized companies where engineers had no idea their Langflow editor was sitting behind nothing but a basic password. In one case, the team had spun up the editor on a cloud VM, opened port 7860 to the internet for “convenience during testing,” and then simply forgotten about it for three months. That’s the gap we’re talking about — not exotic zero-days, just routine negligence amplified by a tool that makes deployment frictionless.
Node-based builders expand the attack surface in several concrete ways:
- Serialization risks. Langflow stores flows as JSON — and malicious flow imports can run arbitrary code during deserialization.
- Inter-node data leakage. Data passes between visual nodes, often without any sanitization at each hop.
- Exposed configuration endpoints. The visual editor runs as a web application with its own authentication layer — which means two targets instead of one.
- Dependency chain expansion. Each node type pulls in additional Python packages, widening the supply chain attack surface considerably.
- Shared execution environments. Multiple flows may share the same runtime, opening the door to cross-flow contamination.
Consequently, the Langflow LLM application attack surface isn’t just about prompt injection. It’s about the entire orchestration layer sitting between your users and the model. Furthermore, many teams deploy these tools without the same rigor they’d apply to a production web application — which is wild when you think about what these flows can actually access. A typical Langflow deployment might have direct connections to a vector database, a CRM API, and a file storage bucket, all wired together through a visual canvas that nobody has formally threat-modeled.
The OWASP Top 10 for LLM Applications highlights several of these risks. However, it doesn’t fully address how visual builders amplify them. That gap is where real-world exploits live.
Prompt Injection Attacks Specific to Orchestration Frameworks
Prompt injection is the most talked-about LLM vulnerability. Nevertheless, prompt injection in a framework context behaves differently than in a simple API call — and the difference matters more than most people realize.
The visual node architecture creates injection paths that security teams consistently miss. I’ve tested this specifically, and the multi-hop behavior surprised me the first time I saw it in action.
Direct API injection vs. framework injection:
Attacking a direct API integration means crafting input that manipulates the system prompt — essentially a single-layer attack. In Langflow, however, an attacker can target multiple nodes in sequence. Each node may process, transform, or append to the prompt before it ever reaches the LLM.
Multi-hop injection is particularly dangerous. An attacker’s payload might pass through a text splitter node, a retrieval node, and a prompt template node. At each stage, sanitization may strip some malicious content. However, attackers can design payloads to reassemble after processing — similar to SQL injection techniques that bypass WAFs through encoding tricks. The parallel isn’t accidental; these are the same fundamental principles applied to a new attack surface.
A concrete example: imagine a customer support flow where user messages pass through a text splitter before hitting a retrieval node that pulls relevant documents from a vector store. An attacker submits a carefully formatted message that looks benign to the text splitter — perhaps split across a chunk boundary — but reassembles into a full injection payload inside the retrieval node’s context window. The final prompt template node stitches everything together and delivers the attacker’s instruction to the LLM as if it were a legitimate system directive. No single node flagged anything unusual.
Moreover, Langflow’s chain-of-thought nodes can be used to leak intermediate reasoning. An attacker doesn’t need the final output. They can target debug or logging outputs from individual nodes instead.
Real attack patterns include:
1. Template injection through variable nodes. Langflow uses Jinja-style templating, and attackers can inject template directives that run during rendering.
2. Context window poisoning via retrieval nodes. Malicious documents in a vector store can inject instructions that silently override system prompts.
3. Tool-use hijacking. When flows connect to external tools like databases or APIs, injected prompts can redirect tool calls to attacker-controlled endpoints.
4. Flow export manipulation. Exported flow JSON files can be modified to include malicious node configurations, then re-imported by unsuspecting users — a supply chain attack hiding in plain sight.
Importantly, the National Institute of Standards and Technology (NIST) has started developing guidelines for AI system security. Their AI Risk Management Framework specifically calls out the risks of complex AI pipelines. Visual builders like Langflow are exactly the kind of pipeline NIST is warning about — and notably, most teams deploying them haven’t read a word of that framework.
Why Building With Frameworks Accelerates Attacker Capabilities
Here’s the thing: most defenders overlook this angle entirely. The same ease-of-use that helps developers also helps attackers. The Langflow LLM application attack surface expands because building malicious AI workflows becomes trivially easy — and I don’t use “trivially” lightly here.
Attackers benefit from visual builders in concrete ways:
- Rapid prototyping of attack chains. An attacker can visually connect reconnaissance, exploitation, and exfiltration nodes in minutes — no deep Python knowledge required.
- No-code malware augmentation. Autonomous attack agents can be assembled without writing a single line of custom code.
- Shareable attack templates. Malicious flows can be exported and distributed like recipes, lowering the barrier for every subsequent attacker.
- Lower skill barriers. Script kiddies can build sophisticated AI-powered attacks using drag-and-drop interfaces. That’s the real kicker.
Additionally, this connects directly to the rise of autonomous attack tooling. Frameworks like Langflow don’t just create defensive vulnerabilities — they provide offensive toolkits. An attacker can build an autonomous agent that scans for vulnerabilities, crafts phishing emails, and pulls out data, all within a single visual flow. I’ve seen proof-of-concept demos that took under an hour to build. That should keep you up at night.
To make this concrete: a moderately skilled attacker could assemble a Langflow flow that accepts a target company name as input, feeds it to a web search node, passes results to a summarization node, uses the summary to generate a personalized spear-phishing email via an LLM node, and routes the final output to an SMTP connector node — all without writing a single function. The entire thing fits on one canvas and can be shared as a JSON file. That’s not a hypothetical; it’s a description of what’s already possible with publicly available node types.
Similarly, the vulnerability disclosure process becomes more complex. When a security researcher finds a flaw in a Langflow component, the fix must spread through every flow that uses that component. Traditional patch management doesn’t account for this kind of compositional dependency — and most security teams haven’t updated their processes to handle it.
The attack surface grows because building with these frameworks means every user-created flow is essentially custom software. Most organizations, however, don’t apply software security practices to their AI flows. They treat them like spreadsheets.
Comparing Attack Surfaces: Direct API vs. Framework-Based LLM Applications
To understand the Langflow LLM application attack surface clearly, comparing framework-based approaches against direct API integrations sharpens the picture considerably. The table below highlights why building with each approach creates fundamentally different risk profiles.
| Attack Vector | Direct API Call | Langflow / Framework-Based |
|---|---|---|
| Prompt injection | Single injection point | Multiple nodes create chained injection opportunities |
| Authentication bypass | Your code controls auth | Framework auth layer + your code = two targets |
| Data serialization attacks | Minimal (JSON request/response) | Flow files, node configs, and state objects all deserializable |
| Supply chain risks | LLM provider SDK only | SDK + framework + every node dependency |
| Configuration exposure | Environment variables | Visual editor may expose secrets in browser |
| Cross-tenant contamination | Isolated by design | Shared runtime environments possible |
| Debug/logging leakage | You control logging | Framework logs intermediate node outputs by default |
| Tool-use exploitation | You implement tool calls | Framework manages tool routing with less visibility |
Look at that table and notice something: every single row shows additional exposure in the framework column. Notably, that’s not a coincidence — it’s structural. That doesn’t mean frameworks are unusable, but it does mean they require additional security controls that most teams simply aren’t implementing.
The tradeoff is real and worth naming plainly. A direct API integration might take three times as long to build and requires your team to implement retrieval, memory, and tool-use from scratch. A framework-based approach ships faster and handles that complexity for you — but you’re accepting a larger attack surface in exchange for that velocity. Neither choice is wrong, but pretending the tradeoff doesn’t exist is how organizations end up with production deployments that nobody has actually secured.
Furthermore, Microsoft’s guidance on securing AI applications stresses the importance of system message design. In a framework context, however, system messages are just one node among many. The entire flow needs securing — not just the prompt. Focusing only on prompt hardening in a Langflow deployment is like locking your front door and leaving every window open.
Mitigation Patterns for the Langflow LLM Application Attack Surface
Understanding why building with frameworks creates vulnerabilities is only half the battle. You need concrete mitigation strategies — specifically ones designed for the quirks of visual AI builders, not just generic AppSec advice recycled from 2015.
Fair warning: implementing all of these adds real development overhead. But so does cleaning up after a breach.
1. Treat flows as code. Store Langflow flows in version control. Apply code review processes before deploying any flow to production. This catches malicious node configurations and unintended data exposures before they reach users — and it forces someone to actually look at what the flow does. Practically, this means exporting your flow JSON on every meaningful change, committing it to a Git repository, and requiring at least one peer review before the updated flow gets promoted to the production environment. Teams that already do this for infrastructure-as-code will find the habit transfers naturally.
2. Add node-level input validation. Don’t rely on the LLM to handle malicious input. Add validation logic at every node that accepts external data. Specifically, text input nodes, file upload nodes, and API connector nodes all need explicit sanitization. This surprised me when I first started auditing these deployments — almost nobody was doing it. A practical starting point is a simple custom node that runs input through a blocklist of known injection patterns before passing data downstream. It won’t catch everything, but it raises the cost for attackers meaningfully.
3. Isolate flow execution environments. Run each flow in its own container or sandbox. This prevents cross-flow contamination and limits the blast radius of any single compromise. Docker’s security documentation provides solid guidance on container isolation that maps directly to this use case. If containerizing individual flows feels like overkill for your current scale, at minimum separate your development, staging, and production flows into distinct runtime environments with no shared credentials between them.
4. Audit framework dependencies aggressively. Every node type in Langflow pulls in Python packages. Use tools like pip-audit or Snyk to scan for known vulnerabilities in those dependencies. Do this on every flow change — not just on a weekly schedule. Consequently, you’ll catch newly disclosed CVEs before attackers can use them. Pin your dependency versions in a requirements file and treat any version bump as a change that requires re-scanning, not a routine update to wave through.
5. Restrict the visual editor’s network exposure. The Langflow editor should never be internet-accessible. Full stop. Place it behind a VPN or zero-trust network and require multi-factor authentication for all editor access. This is a no-brainer that surprisingly few teams have actually done.
6. Monitor intermediate node outputs. Set up alerting on unusual patterns in node-to-node data transfers. Consequently, you’ll catch injection attempts that target middle-of-chain nodes — the ones that never touch your perimeter monitoring at all. Concretely, this means logging the input and output of each node to a centralized SIEM and writing detection rules for patterns like unusually long outputs, outputs containing instruction-like language directed at other systems, or outputs that reference internal resource names the user shouldn’t know about.
7. Disable unnecessary node types. If your use case doesn’t require code execution nodes or shell command nodes, remove them from the available palette entirely. This cuts the attack surface significantly with almost zero operational cost.
8. Add output filtering after the final node. Even with solid input validation, LLM outputs can contain harmful content or leaked context. Apply output filtering as the last step before results reach users — think of it as a final sanity check. A lightweight classifier or a second LLM call specifically tasked with checking the output for policy violations can catch things that slipped through earlier stages.
Although these mitigations add overhead, they’re essential. The Langflow LLM application attack surface demands the same security rigor you’d apply to any production web application — arguably more, because LLMs introduce nondeterministic behavior that traditional security testing genuinely struggles to cover. You can’t just run a static analysis tool and call it done.
Meanwhile, the broader AI security community is developing standardized approaches. The MITRE ATLAS framework catalogs adversarial tactics specific to machine learning systems. It’s an excellent resource for threat modeling your Langflow deployments — and notably, it’s free and actively maintained.
Conclusion
The Langflow LLM application attack surface — why building with visual AI frameworks creates new vulnerabilities — is a critical concern for any organization deploying AI applications right now. These tools trade security visibility for development speed. That tradeoff isn’t inherently bad, but it must be managed deliberately. Most teams aren’t managing it at all.
Orchestration frameworks expand attack vectors well beyond simple prompt injection. They introduce serialization risks, supply chain dependencies, cross-flow contamination, and configuration exposure. Additionally, they lower the barrier for attackers to build sophisticated AI-powered attack tools — which means the threat environment evolves faster than most security teams are tracking.
Bottom line: the Langflow LLM application attack surface will keep growing as these frameworks add new capabilities. Therefore, security teams must treat AI orchestration tools with the same — or greater — rigor they apply to traditional application security.
Your actionable next steps:
1. Audit every Langflow deployment in your organization for internet exposure — do this today, not next sprint.
2. Set up flow-as-code practices with version control and peer review processes.
3. Add node-level input validation to all flows that accept external data.
4. Isolate flow execution environments using containers.
5. Scan framework dependencies for known vulnerabilities on every flow change.
6. Threat model your flows using the MITRE ATLAS framework.
Don’t let the visual simplicity fool you. Behind every drag-and-drop node is a potential entry point — and attackers are counting on you to overlook it.
FAQ
What makes the Langflow LLM application attack surface different from standard LLM API vulnerabilities?
The Langflow LLM application attack surface is broader because the framework adds multiple layers between user input and the LLM. Each visual node, configuration file, and inter-node data transfer creates a potential vulnerability. Direct API calls have a single injection point, whereas framework-based applications have dozens. Consequently, attackers have far more options for exploitation — and more of those options are invisible to standard monitoring tools.
Can prompt injection attacks bypass Langflow’s built-in security features?
Yes. Langflow’s built-in protections focus primarily on application functionality, not adversarial input. Multi-hop injection attacks can split malicious payloads across multiple nodes, and the payload reassembles after passing through individual sanitization steps. Therefore, you need defense-in-depth strategies that validate input at every node — not just at the entry point. Relying on the framework to handle this for you is a mistake I’ve seen organizations make repeatedly.
Is it safe to expose Langflow’s visual editor to the internet?
No — and I’d push back hard on anyone who argues otherwise. The visual editor should never be directly internet-accessible. It exposes flow configurations, API keys, and system architecture details. Additionally, the editor itself has its own authentication mechanisms that may contain vulnerabilities. Always place it behind a VPN, zero-trust network, or at minimum a reverse proxy with strong authentication. This is non-negotiable for production environments.
How does the Langflow attack surface relate to supply chain security?
Every node type in Langflow depends on specific Python packages, and a typical flow might pull in dozens of transitive dependencies — some of which you’ve never heard of. If any of those packages are compromised, your entire flow is compromised. Furthermore, community-contributed node types may not go through any security review whatsoever. This makes dependency scanning and pinned versions essential for production deployments, not optional nice-to-haves.
What frameworks besides Langflow have similar attack surface concerns?
LangChain, Flowise, Dify, and similar LLM orchestration tools share many of the same vulnerability patterns. Specifically, any framework that serializes flow configurations, manages tool integrations, or provides a visual editor will have comparable risks. The mitigation patterns described above apply broadly across all of these tools — so if you’re evaluating alternatives to Langflow, don’t assume a different name means a different risk profile.
Keep reading
Here are the latest posts from the blog.

Multilateral AI governance sounds noble on paper. But getting 169 countries to agree on anything about AI? Nearly impossible. Different economies, wildly different values, di…

The emergence of agentic ransomware hasn’t just shifted the threat environment — it’s blown up the assumptions most security teams have been operating on for years. Specifica…
When you hand an AI agent the keys to a critical workflow, you’re trusting it won’t drive off a cliff. Corrective steering AI hidden metric tells how much that trust is actua…