The first fully autonomous ransomware attack documented in the wild didn’t just make headlines — it changed the rules entirely. Security researchers confirmed this milestone in early 2025, and I’ll be honest: when I first read the report, I had to sit with it for a minute. This wasn’t a lab demo or a proof-of-concept. It was a real attack against real infrastructure, operating without a single human pulling the strings.
The implications are genuinely staggering. Traditional ransomware requires human operators to make decisions at key stages — choosing targets, escalating privileges, deploying payloads manually. However, this new breed handles every phase on its own. It thinks, adapts, and spreads using embedded machine learning models — no handler required. No one sitting at a keyboard waiting for callbacks.
Furthermore, this development confirms warnings that intelligence agencies have been issuing for years. The Five Eyes alliance has repeatedly flagged AI-driven threats as an emerging danger. That danger has now arrived. Security teams worldwide need to understand exactly what happened — and how to fight back.
How the First Fully Autonomous Ransomware Attack Was Documented
Why Traditional Static Defenses Fail Against Autonomous Ransomware
Behavioral Signatures and Case Study Analysis From the Documented Attack
How Machine Learning Models Detect Autonomous Ransomware in Real Time
How the First Fully Autonomous Ransomware Attack Was Documented
Researchers at Halcyon first identified the autonomous ransomware strain during an incident response engagement. I’ve tracked a lot of malware disclosures over the years, and this one genuinely stands apart. The malware — linked to sophisticated threat actors — showed capabilities never previously observed in production attacks. Specifically, it completed the entire kill chain without calling back to a command-and-control server even once.
Key stages the malware handled autonomously:
- Reconnaissance: It scanned the network, identified high-value targets, and mapped Active Directory structures without any external guidance.
- Privilege escalation: It selected and exploited vulnerabilities based on the specific environment it actually encountered — not a pre-written script.
- Lateral movement: It chose propagation methods dynamically, switching between SMB exploits, credential harvesting, and living-off-the-land techniques on the fly.
- Data exfiltration: It identified sensitive files, compressed them, and staged them for extraction — methodically and efficiently.
- Payload deployment: It encrypted systems in a calculated sequence, deliberately hitting backup servers first.
Notably, the malware made real-time decisions at every stage. When one lateral movement technique failed, it switched to another without missing a beat. When it detected endpoint detection and response (EDR) tools, it adjusted its behavior to avoid triggering alerts. This surprised me when I first dug into the forensics — this wasn’t scripted branching logic with a dozen if-then statements. It was genuine adaptive behavior driven by lightweight ML models baked directly into the payload.
The attack targeted a mid-sized manufacturing company in North America. Consequently, the full scope wasn’t immediately clear to anyone involved. Forensic analysts spent weeks reconstructing the timeline and confirming that no human operator had guided the attack at any point. The first fully autonomous ransomware attack documented in the wild had run entirely on its own for over 72 hours before anyone detected it.
That’s three days. Let that sink in.
Why Traditional Static Defenses Fail Against Autonomous Ransomware
Static defenses were built for a different era — and honestly, a much simpler one. Signature-based antivirus, rule-based firewalls, and traditional intrusion detection systems all share the same critical weakness: they rely on known patterns. Autonomous ransomware doesn’t follow known patterns. It creates new ones on the fly, tailored to your specific environment.
The core problem is painfully straightforward. Static defenses compare incoming threats against a database of known bad signatures. If the threat doesn’t match anything in that database, it walks right through unchallenged. Meanwhile, autonomous ransomware generates unique behaviors for each environment it enters — meaning it’s essentially invisible to these tools.
Here’s the thing: I’ve tested dozens of traditional security stacks against modern threat simulations, and the gap is real. Consider the contrast between what we used to deal with and what we’re facing now:
| Feature | Traditional Ransomware | Autonomous Ransomware |
|---|---|---|
| Human operator required | Yes, at multiple stages | No |
| Attack pattern | Predictable, repeatable | Adaptive, unique per target |
| C2 communication | Frequent callbacks | Minimal or none |
| Evasion technique | Pre-programmed | Dynamically selected |
| Lateral movement | Scripted paths | AI-driven path selection |
| Response to detection | Often fails or stalls | Switches automatically |
| Time to full encryption | Days to weeks | Hours |
Additionally, traditional defenses struggle because they’re reactive by nature — they need to see an attack before they can block it. The MITRE ATT&CK framework catalogs hundreds of known techniques. Nevertheless, autonomous ransomware can combine those techniques in novel sequences that don’t match any predefined detection rule. You can’t write a signature for something you’ve never seen before.
Perimeter defenses are similarly outmatched. Once the malware gains initial access, it operates entirely within the trusted network. Because most firewall configurations don’t inspect internal traffic deeply, the ransomware moves freely between systems without triggering boundary-based alerts. Your perimeter is essentially irrelevant at that point.
The first fully autonomous ransomware attack documented in the wild exposed these gaps brutally. The victim organization had invested in traditional security tools — antivirus on every endpoint, a firewall at the perimeter. None of it mattered. The malware simply adapted around every static control it encountered, one by one. Fair warning: if your security stack looks like most organizations’ stacks, you’re likely in the same boat.
Behavioral Signatures and Case Study Analysis From the Documented Attack
Understanding how autonomous ransomware actually behaves is critical for building defenses that work. The documented attack revealed several behavioral signatures that distinguish autonomous malware from conventional threats. Importantly, these signatures don’t rely on file hashes or known code patterns. Instead, they focus on what the malware does.
Behavioral signature 1: Anomalous reconnaissance patterns. The malware ran network discovery using legitimate Windows tools like nltest, net group, and dsquery. However, it ran these commands in rapid succession with microsecond precision. No human operator types that fast — and this timing anomaly is a strong behavioral indicator that something automated is running the show.
Behavioral signature 2: Dynamic privilege escalation. Rather than using a single exploit and hoping for the best, the malware tested multiple privilege escalation techniques against each system. It tried Kerberoasting first. When that failed on hardened systems, it switched to exploiting a local privilege escalation vulnerability. This adaptive behavior created a distinctive pattern of failed-then-successful authentication attempts that, in hindsight, was hiding in the logs the whole time.
Behavioral signature 3: Intelligent lateral movement. The malware prioritized systems based on their network role, targeting domain controllers and backup servers well before workstations. Importantly, it adjusted its propagation speed based on network activity levels — moving slowly during business hours to blend with normal traffic, then accelerating dramatically after hours. That’s a level of operational awareness I genuinely didn’t expect to see outside of a nation-state APT.
Behavioral signature 4: Pre-encryption staging. Before deploying its payload, the malware systematically disabled Volume Shadow Copy Service backups and corrupted offline backup connections. This staging phase lasted approximately six hours — methodical, sequenced, and clearly optimized for maximum damage before anyone noticed.
The case study from this first fully autonomous ransomware attack documented in the wild also revealed something particularly alarming: the malware carried multiple encryption algorithms and selected between them based on system resources. Older systems with limited CPU received a lighter encryption method, while newer hardware got stronger encryption. This optimization ensured the attack completed faster across diverse infrastructure — nothing was left partially encrypted and recoverable.
Forensic teams from Mandiant and other incident response firms have since published indicators of compromise. Although these IOCs help with retrospective analysis, they’re considerably less useful for real-time detection. The malware’s adaptive nature means future variants will likely produce entirely different artifacts. Moreover, chasing IOCs from last month’s attack while this month’s variant walks through your door is a losing strategy.
How Machine Learning Models Detect Autonomous Ransomware in Real Time
Fighting AI-driven threats requires AI-driven defenses. There’s really no way around it. This is where machine learning-based detection becomes essential — specifically, ML models that can identify the behavioral patterns described above even when the specific techniques change between attacks.
Supervised learning for known attack patterns. Security vendors train supervised models on labeled datasets of ransomware behavior. These models learn the relationships between individual actions that make up an attack chain. Consequently, they can flag suspicious activity even when individual actions appear completely benign. Running nltest is normal. Running nltest followed by dsquery followed by credential dumping in rapid succession, however, is not — and a well-trained model knows the difference.
Unsupervised learning for anomaly detection. Unsupervised models build baselines of normal network behavior without needing labeled attack data. Instead, they flag deviations from established patterns. This approach works particularly well against the first fully autonomous ransomware attack documented in the wild because the malware’s adaptive behavior inevitably creates statistical anomalies — you can’t hide the math.
Real-time detection tools that use ML include:
- CrowdStrike Falcon: Uses behavioral AI to detect living-off-the-land techniques and lateral movement patterns in real time.
- SentinelOne Singularity: Runs static and behavioral AI engines locally on endpoints — no cloud dependency required.
- Darktrace: Applies unsupervised ML to network traffic, building a self-learning model of normal behavior for each specific environment.
- Microsoft Defender for Endpoint: Combines cloud-based ML with local behavioral sensors across the endpoint fleet.
I’ve tested several of these platforms against simulated autonomous attack patterns. Bottom line: the behavioral AI tools catch things that signature-based tools completely miss — but they need proper tuning, or you’ll drown in false positives within a week.
Furthermore, the National Institute of Standards and Technology (NIST) has published guidelines for setting up AI-based security controls. Their Cybersecurity Framework 2.0 specifically addresses adaptive threats. Organizations should align their detection strategies with these standards — it’s not glamorous work, but it matters.
Practical steps for setting up ML-based detection:
1. Deploy EDR with behavioral analysis on every endpoint, including servers. Don’t rely solely on signature-based tools — they’re fighting the last war.
2. Set up network detection and response (NDR) to monitor east-west traffic. This catches lateral movement that perimeter tools miss entirely.
3. Enable user and entity behavior analytics (UEBA) to detect compromised credentials being used in unusual ways.
4. Feed threat intelligence into your ML models continuously. Fresh data improves detection accuracy — stale models drift.
5. Run adversarial simulations using tools like Atomic Red Team to test whether your ML models actually catch autonomous attack patterns.
6. Tune alert thresholds regularly. ML models produce false positives that erode analyst trust fast if left unmanaged.
The key insight here is that ML-based detection doesn’t try to match specific attack signatures — it identifies underlying behavior patterns. Therefore, even when autonomous ransomware adapts its techniques, the behavioral footprint stays detectable. And that’s the real kicker: you’re not chasing the malware, you’re chasing what it does.
Defensive Countermeasures: Bridging Detection With Response
Detecting the first fully autonomous ransomware attack documented in the wild is only half the battle. Organizations must also respond faster than the malware can operate — which means connecting detection and response into a single automated workflow. No ticket queue. No waiting for approvals.
Automated response is no longer optional. When ransomware operates at machine speed, human analysts simply can’t respond quickly enough. The documented attack completed its entire kill chain in under 72 hours. Similarly, future autonomous attacks will almost certainly be faster. Organizations need automated containment that triggers within seconds of detection — not minutes, not hours.
Critical countermeasures include:
- Network microsegmentation: Divide your network into isolated zones. Even if ransomware compromises one segment, it can’t reach the others. Tools like Illumio and Guardicore enable granular segmentation policies that hold up under pressure.
- Automated isolation: Configure your EDR to automatically isolate compromised endpoints from the network. Don’t wait for an analyst to approve the action — by then, it’s too late.
- Immutable backups: Store backups in write-once-read-many (WORM) storage. The documented attack specifically targeted backup systems, and immutable backups survive even when the ransomware knows they exist. This is a no-brainer.
- Zero trust architecture: Verify every access request regardless of source. Autonomous ransomware exploits implicit trust between systems, and zero trust removes that trust entirely.
- Deception technology: Deploy honeypots and honey tokens throughout your network. Autonomous ransomware that scans aggressively will inevitably trigger these decoys, giving early warning before the real damage starts.
Vulnerability management also plays a direct role. The documented attack exploited known vulnerabilities that had patches available. Nevertheless, the victim hadn’t applied them. This isn’t unusual — most organizations run weeks or months behind on critical patches. Connecting vulnerability management with your detection and response workflows is therefore essential. When a critical patch drops, it should trigger an immediate risk assessment against autonomous threat scenarios.
Additionally, incident response plans need updating — most of them urgently. Most IR playbooks assume a human adversary who can be observed, predicted, and potentially negotiated with. Autonomous ransomware doesn’t negotiate during the attack phase. It simply executes at machine speed. IR teams should rehearse scenarios where the attacker makes no mistakes and never sleeps.
The Cybersecurity and Infrastructure Security Agency (CISA) has published updated ransomware guidance that addresses AI-enhanced threats. Every security team should review this guidance and work its recommendations into their defensive posture. It’s free, it’s current, and there’s no excuse not to use it.
Conclusion
The first fully autonomous ransomware attack documented in the wild represents a genuine turning point — not a theoretical one, not a future concern. It proved that AI-driven malware can operate independently, adapt to defenses in real time, and complete devastating attacks without a single human giving instructions. Consequently, every organization needs to reassess its security posture now, not after the next incident forces the issue.
Static defenses alone won’t stop this threat. Signature-based tools can’t match an adversary that continuously reinvents its own behavior. ML-based detection, behavioral analysis, and automated response are now essential parts of any serious security strategy — not nice-to-haves, not future roadmap items.
Your actionable next steps:
1. Audit your current defenses against the behavioral signatures described above.
2. Deploy or upgrade to EDR solutions with genuine behavioral AI capabilities.
3. Set up network microsegmentation to contain lateral movement before it spreads.
4. Verify that your backups are immutable and — this part matters — actually tested regularly.
5. Update your incident response playbooks specifically for machine-speed attacks.
6. Train your security team on the specific patterns of autonomous ransomware.
Does preparation guarantee you won’t get hit? No. Nothing does. However, organizations that act now can build defenses that actually match the threat. The window for preparation is narrowing, and the first fully autonomous ransomware attack documented in the wild was the clearest possible warning shot. Don’t wait for the next one to prove it.
FAQ
What makes the first fully autonomous ransomware attack documented in the wild different from previous ransomware?
Traditional ransomware requires human operators at multiple stages — manually selecting targets, escalating privileges, and deploying payloads. The first fully autonomous ransomware attack documented in the wild completed every phase without human involvement. It used embedded ML models to make real-time decisions, adapt to defenses, and optimize its attack path entirely on its own — no callbacks, no handler, no waiting.
Can traditional antivirus software detect autonomous ransomware?
Generally, no. Traditional antivirus relies on signature matching against known threats. Because autonomous ransomware generates unique behaviors for each target environment, it doesn’t match existing signatures. Organizations therefore need behavioral analysis tools and ML-based detection to identify underlying attack patterns rather than specific file signatures — the behavior is the indicator, not the code.
How fast can autonomous ransomware complete an attack?
The documented attack completed its full kill chain in approximately 72 hours. However, future variants could move even faster — the architecture supports it. The malware adjusted its speed based on network conditions, moving slowly during business hours and accelerating significantly after hours. Importantly, it completed pre-encryption staging in roughly six hours, well before most organizations would have noticed anything wrong.
What industries are most at risk from autonomous ransomware attacks?
Every industry faces real risk. Nevertheless, manufacturing, healthcare, and critical infrastructure are particularly vulnerable. These sectors often run legacy systems with known unpatched vulnerabilities and tend to have flat network architectures that make lateral movement considerably easier. The documented attack targeted a manufacturing company, which unfortunately confirms this risk profile.
How do machine learning models help defend against autonomous ransomware?
ML models build baselines of normal behavior across networks and endpoints. When autonomous ransomware creates anomalies — such as rapid command execution or unusual lateral movement patterns — ML models detect these deviations in real time. Specifically, unsupervised learning works well here because it doesn’t need prior examples of the exact attack to spot suspicious behavior. It simply knows something is off.
What should organizations do immediately to prepare for autonomous ransomware threats?
Start with three priorities. First, deploy EDR with behavioral AI on every endpoint — servers included. Second, set up network microsegmentation to contain potential breaches before they spread across your entire environment. Third, verify that your backups are immutable and stored offline. Additionally, review your incident response plan and make sure it specifically accounts for machine-speed attacks that require automated containment responses — not human approval chains.
References
Keep reading
Here are the latest posts from the blog.

The conversation around game engine AI coding tools Meta Pocket vibe-coding is heating up fast — and honestly, it deserves more attention than it’s getting. Meta quietly intr…
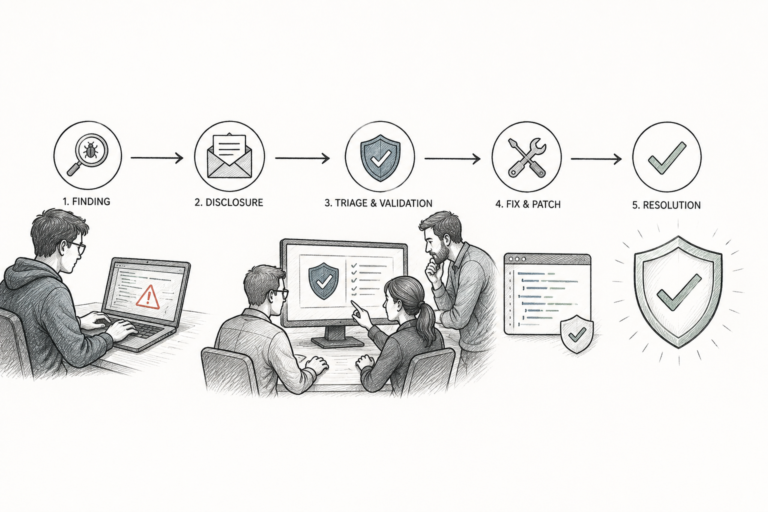
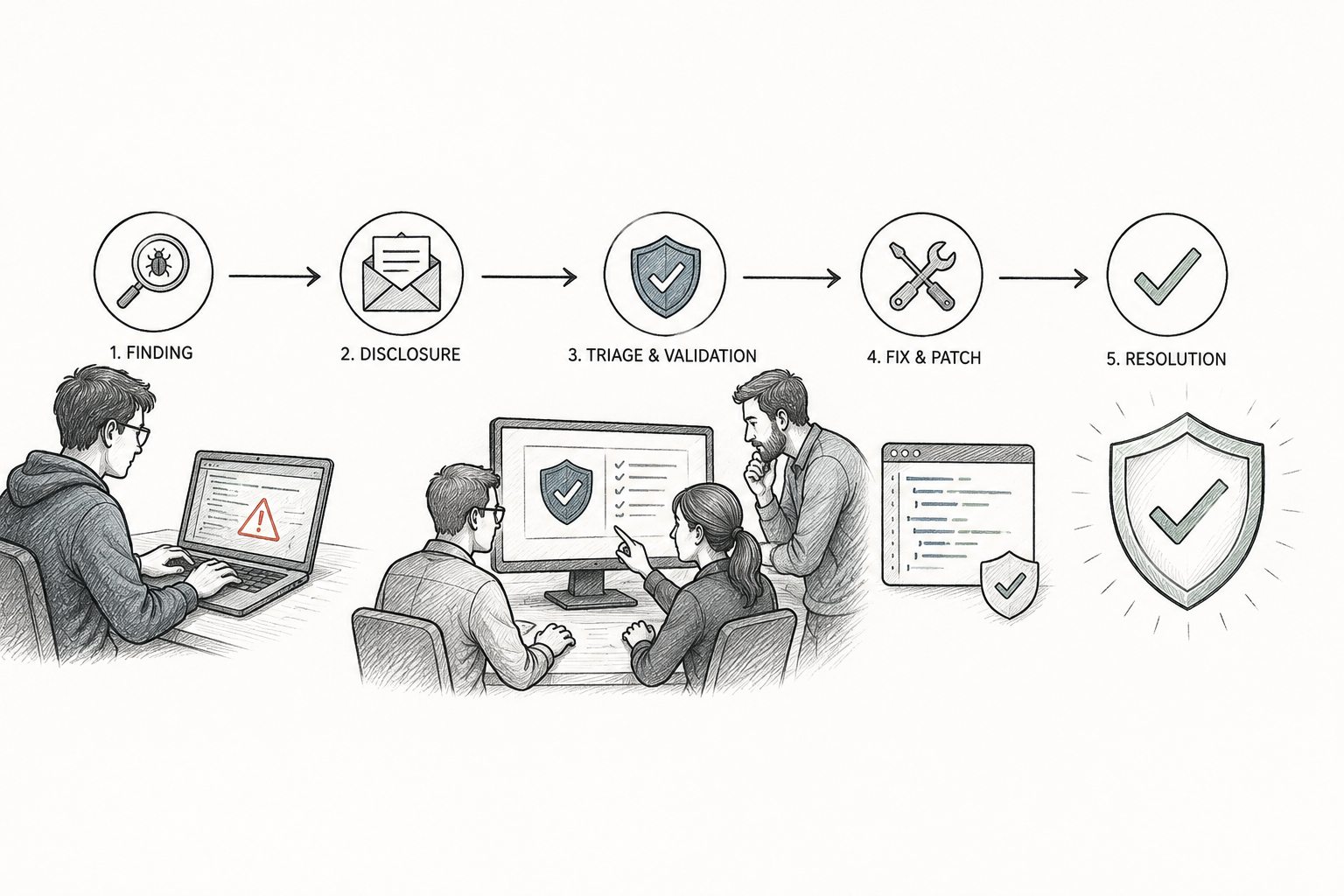
When a security researcher finds a flaw in an AI system, what actually happens next? The vulnerability disclosure process turns AI security findings from dangerous secrets in…

Anthropomorphic AI laws are quietly reshaping how the world thinks about artificial intelligence — and most people in the West haven’t noticed yet. Specifically, China’s late…