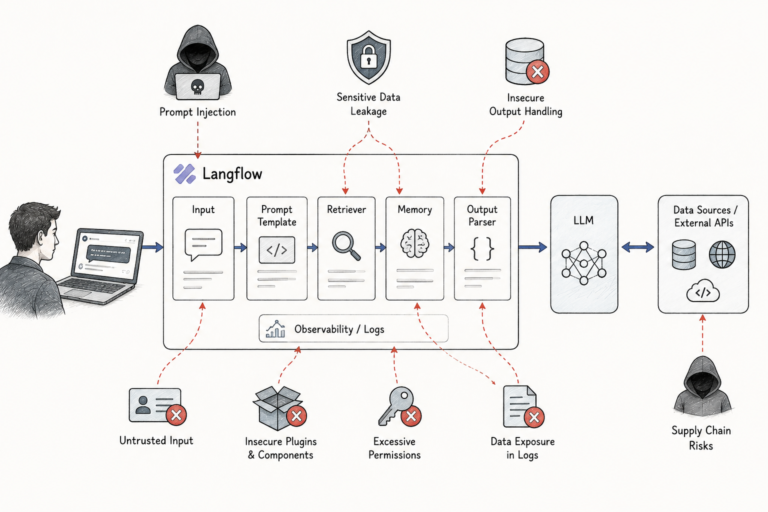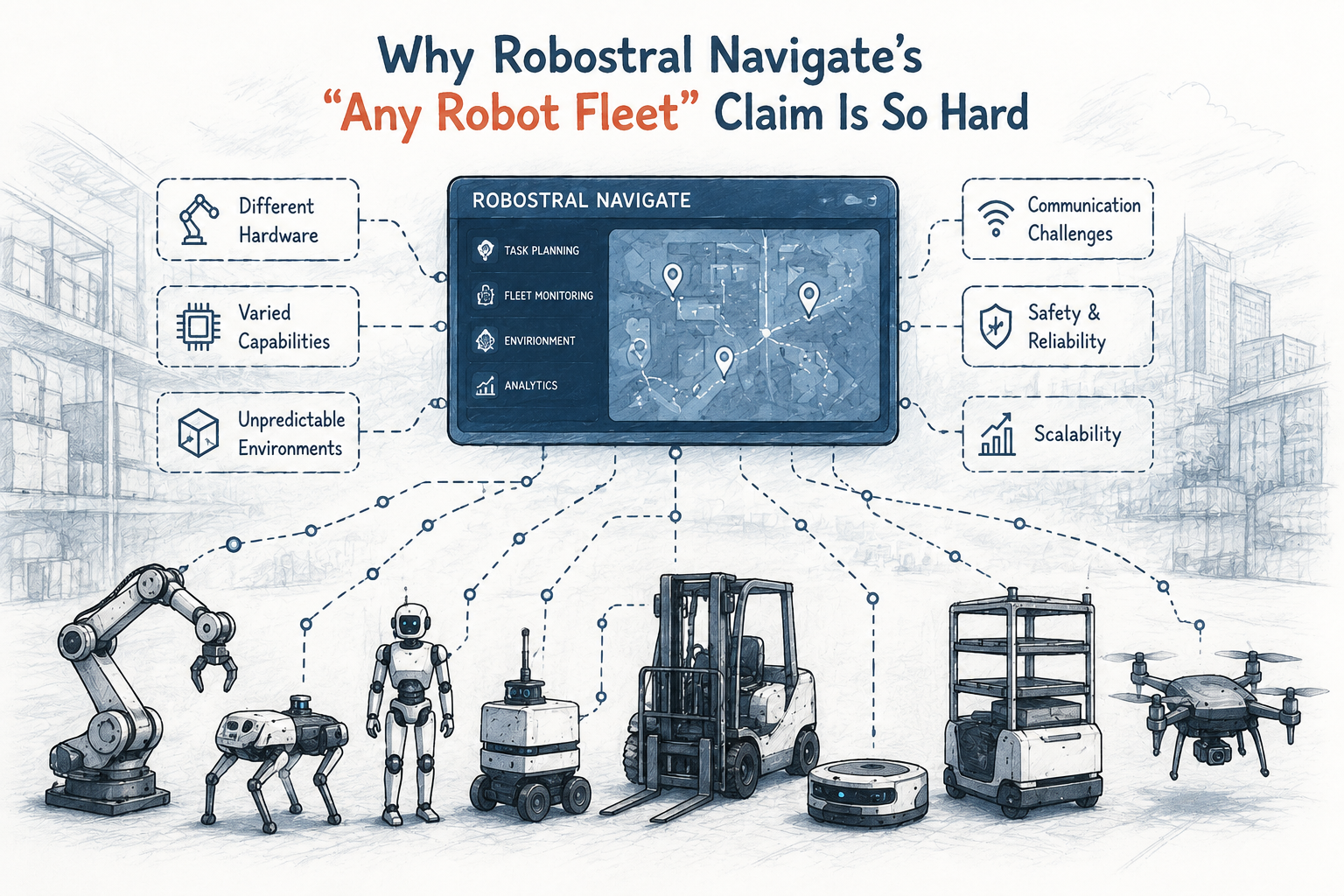
The promise sounds almost too good to be true. One software platform, every robot in your fleet, regardless of who built them. Why hardware agnostic AI why Robostral Navigate’s ‘any robot fleet’ claim generates so much excitement is obvious — it would eliminate vendor lock-in overnight. However, the engineering reality behind that promise tells a very different story.
Robostral Navigate isn’t alone in making this pitch. Dozens of robotics middleware companies claim universal compatibility. Nevertheless, the gap between marketing slides and factory floors remains enormous — and I’d argue it’s wider than most buyers realize. Understanding why requires looking beneath the surface at APIs, firmware, and the genuinely messy physics of real-world deployment.
The Allure and Architecture of Hardware-Agnostic AI
API Standardization Gaps That Break Universal Control
Firmware Lock-In and the Vendor Control Problem
Real-World Deployment Friction Nobody Talks About
Where Hardware-Agnostic Approaches Work (and Where They Don’t)
The Allure and Architecture of Hardware-Agnostic AI
Why hardware agnostic AI why Robostral Navigate’s ‘any robot fleet’ claim resonates so strongly comes down to one word: cost. Enterprises running mixed fleets from companies like Universal Robots, FANUC, and Boston Dynamics routinely spend millions maintaining separate control stacks. A single abstraction layer would be genuinely transformative — I get why procurement teams light up when they hear it.
The theoretical architecture is straightforward enough. You build a middleware layer that translates high-level commands into manufacturer-specific instructions. Specifically, this means creating a universal command set that maps to each robot’s native API. Think of it like a universal remote for your entire robot fleet.
But universal remotes rarely work perfectly. And robots are infinitely more complex than televisions.
Why the abstraction model breaks down:
- Each manufacturer uses proprietary communication protocols
- Sensor data formats differ wildly between platforms
- Safety systems operate under different certification standards
- Real-time control loops have manufacturer-specific timing requirements
- Firmware updates can break compatibility without warning
Moreover, the problem compounds with scale. Supporting two robot brands is manageable. Supporting twenty requires exponential testing effort. Consequently, most hardware agnostic AI platforms quietly limit their “any robot” claim to a curated list of supported models. That’s the fine print nobody highlights in the demo.
The Robot Operating System (ROS) project has spent over fifteen years trying to solve this exact problem. Although ROS has become an industry standard for research, even it struggles with production-grade hardware abstraction. That context matters enormously when you’re evaluating Robostral Navigate’s ambitions.
API Standardization Gaps That Break Universal Control
The biggest obstacle facing hardware agnostic AI why Robostral Navigate’s ‘any robot fleet’ claim is API fragmentation. No USB standard for robotics exists. No universal plug-and-play protocol has emerged — and frankly, I don’t see one arriving soon.
The current API picture looks like this:
| Manufacturer | Protocol Type | Real-Time Capable | Open Documentation |
|---|---|---|---|
| FANUC | Proprietary (ROBOGUIDE) | Yes | Limited |
| ABB | Proprietary (RobotStudio) | Yes | Partial |
| Universal Robots | URScript (semi-open) | Yes | Yes |
| Boston Dynamics | gRPC-based API | Limited | Partial |
| KUKA | Proprietary (KRL) | Yes | Limited |
Notice the pattern. Most major manufacturers use proprietary protocols. Furthermore, even when APIs are documented, they expose wildly different capability levels. One robot might offer joint-level torque control through its API, while another exposes only end-effector position commands. That gap is enormous in practice.
This isn’t just an inconvenience — it’s a fundamental architectural mismatch. Specifically, a hardware agnostic AI layer must choose the lowest common denominator of capability. That means your expensive force-sensitive robot arm gets dumbed down to match your budget model’s limited API. I’ve seen this catch engineering teams off guard. They assumed “compatible” meant “fully capable.”
Additionally, API versioning creates ongoing headaches. Manufacturers update their APIs on their own schedules. A firmware update from KUKA might remove endpoints that Robostral Navigate depends on. Meanwhile, ABB might add new safety parameters that need immediate integration. Fair warning: that maintenance burden lands squarely on your team.
The OPC Foundation has tried to create unified industrial communication standards through OPC UA. Nevertheless, adoption remains inconsistent across robotics manufacturers. The standard handles data exchange reasonably well but doesn’t address real-time motion control adequately — and real-time control is where it counts.
Critical API gaps that persist:
1. No standard error code taxonomy across manufacturers
2. Safety state reporting varies in detail and format
3. Coordinate frame conventions differ between brands
4. Payload capacity reporting uses inconsistent units and methods
5. Tool center point calibration procedures aren’t portable
So when Robostral Navigate claims universal fleet control, ask which API features actually transfer. The answer is usually disappointing.
Firmware Lock-In and the Vendor Control Problem
Beyond APIs, hardware agnostic AI why Robostral Navigate’s ‘any robot fleet’ claim faces resistance rooted in firmware. Manufacturers deliberately design firmware to maintain control over their ecosystems. This isn’t accidental — it’s a business strategy, and a pretty effective one.
Firmware lock-in operates on several levels. First, safety-certified firmware can’t be modified without voiding certifications. The International Organization for Standardization (ISO) requires that safety-critical robot systems maintain validated software stacks. Inserting a third-party abstraction layer can invalidate those certifications — and that’s not a theoretical risk. It’s happened to real deployments.
Second, manufacturers embed proprietary optimization algorithms in firmware. A FANUC robot’s path planning is tuned specifically for FANUC hardware. Consequently, bypassing native firmware with generic commands often produces worse motion quality. The robot technically works, but it moves slower, less smoothly, or less accurately. This surprised me the first time I saw it benchmarked side-by-side.
The firmware lock-in hierarchy:
- Level 1: Communication protocols — Encrypted or undocumented serial protocols
- Level 2: Safety systems — Certified safety controllers that reject unauthorized commands
- Level 3: Motion planning — Proprietary algorithms optimized for specific actuators
- Level 4: Sensor fusion — Custom sensor processing pipelines
- Level 5: Predictive maintenance — Manufacturer-specific diagnostic systems
Although some manufacturers have moved toward more open architectures, the trend is slow. Moreover, openness often comes with strings attached. Universal Robots offers a relatively open platform, but advanced features still require their proprietary ecosystem.
Here’s the thing: this lock-in isn’t purely technical — it’s also contractual. Many robot purchase agreements include clauses that void warranties if third-party control software is used. For enterprise buyers, that warranty risk alone can kill a hardware agnostic AI deployment before it starts.
The practical result? Robostral Navigate and similar platforms typically work best with a narrow subset of robots. They achieve broad compatibility on paper by supporting basic movement commands. But the rich, manufacturer-specific features that justify premium robot hardware? Largely inaccessible.
Real-World Deployment Friction Nobody Talks About
Marketing demos happen in controlled environments. Factories don’t.
The hardware agnostic AI why Robostral Navigate’s ‘any robot fleet’ claim meets its harshest reality check during actual deployment. I’ve talked to enough integration engineers to know that the gap between “it worked in the demo” and “it works on our floor” is where projects go to die.
Common deployment friction points:
1. Network latency variations — Different robots have different real-time communication needs. A 2ms delay that’s fine for a mobile platform could cause a welding arm to produce defective joints.
2. Environmental sensor conflicts — Robots from different manufacturers may use overlapping LiDAR frequencies. Specifically, two robots scanning the same area can create interference that confuses both systems.
3. Power management differences — Battery-powered mobile robots and grid-connected industrial arms have fundamentally different operational profiles. A universal controller must handle both gracefully.
4. Calibration drift — Each robot brand drifts differently over time. Similarly, recalibration procedures vary significantly between manufacturers.
5. Emergency stop coordination — Perhaps the most critical issue. When one robot triggers an emergency stop, every robot in the fleet must respond correctly. Nevertheless, e-stop protocols differ between manufacturers, and getting this wrong isn’t just a productivity problem.
The National Institute of Standards and Technology (NIST) has documented these interoperability challenges in detail. Their research consistently shows that multi-vendor robot coordination requires far more engineering effort than single-vendor deployments. This isn’t opinion — it’s in their published findings.
Furthermore, consider the human factor. Technicians trained on FANUC systems think differently than those trained on ABB platforms. A hardware agnostic AI platform must provide interfaces that both groups can use effectively. That’s a UX challenge as much as a technical one, and it’s almost never mentioned in vendor conversations.
The deployment timeline tells the real story. Single-vendor robot cells typically deploy in weeks. Multi-vendor fleets controlled through abstraction layers often take months. Ongoing maintenance costs can exceed the initial integration investment. Consequently, the total cost picture looks very different from what the sales deck suggests.
Where Hardware-Agnostic Approaches Work (and Where They Don’t)
Not everything about hardware agnostic AI why Robostral Navigate’s ‘any robot fleet’ claim represents overreach. There are genuine use cases where abstraction layers deliver real value. However, they’re narrower than the marketing suggests — and being honest about that distinction is actually useful.
Where hardware-agnostic AI works well:
- Fleet monitoring and analytics dashboards
- High-level task scheduling and orchestration
- Warehouse mobile robot coordination (AMRs)
- Simulation and digital twin environments
- Non-real-time data collection and reporting
Where it consistently falls short:
- Precision manufacturing with tight tolerances
- Force-sensitive assembly operations
- Safety-critical surgical or defense applications
- High-speed pick-and-place operations
- Multi-robot collaborative manipulation
The distinction comes down to timing and precision. Additionally, it depends on how close to the hardware the software needs to operate. Monitoring a fleet of warehouse robots from a dashboard? Absolutely achievable — I’ve seen this work well. Coordinating two different robot arms to jointly assemble a smartphone? Not with current abstraction technology. The real kicker is that the high-value use cases almost always fall in the second category.
Notably, companies like Intrinsic (an Alphabet company) are working on this problem with significant resources. Even with Google-level engineering talent and funding, they’ve acknowledged how hard true hardware abstraction really is. Their approach focuses on specific industrial workflows rather than claiming universal compatibility — and I think that intellectual honesty is worth noting.
Meanwhile, the Eclipse Foundation’s Cyclone DDS project provides open-source middleware for robot communication. It handles data distribution well but still requires manufacturer-specific adapters for actual robot control.
The honest assessment? Hardware agnostic AI platforms work best as orchestration layers sitting above manufacturer-specific control stacks. They add value through coordination, not replacement. Robostral Navigate’s claim of controlling “any robot fleet” likely works at the orchestration level. But the low-level control that determines actual robot performance still lives in proprietary territory — and probably will for a while.
What Buyers Should Actually Evaluate Before Committing
Understanding why hardware agnostic AI why Robostral Navigate’s ‘any robot fleet’ claim deserves scrutiny helps buyers ask better questions. Don’t accept compatibility claims at face value. Dig into the specifics — vendors who can’t answer detailed questions probably haven’t done the detailed work.
Essential evaluation criteria:
1. Supported feature depth — Ask for a feature matrix showing which capabilities work with each supported robot. Basic movement isn’t enough. You need to know about force control, vision integration, and safety system access.
2. Latency benchmarks — Request real-time performance data comparing native control versus abstraction layer control. Specifically, look for worst-case latency numbers, not averages. Averages hide the failures.
3. Certification status — Verify whether using the abstraction layer keeps your robots’ safety certifications intact. This is non-negotiable for production environments.
4. Update synchronization — Ask how quickly the platform adapts to manufacturer firmware updates. A three-month lag could leave your fleet exposed.
5. Fallback procedures — Understand what happens when the abstraction layer fails. Can each robot revert to native control independently?
Furthermore, request references from customers running the exact robot combination you plan to deploy. Generic testimonials don’t prove compatibility with your specific hardware mix. If a vendor can’t produce those references, that’s your answer.
Additionally, negotiate contractual protections. Because the vendor claims universal compatibility, they should guarantee performance levels across your specific fleet. Vague compatibility claims without performance guarantees are red flags — full stop.
The robotics industry is maturing rapidly. Consequently, standards will improve over time. But today, the hardware agnostic AI dream remains only partly realized. Smart buyers plan accordingly, budgeting for integration work that vendors won’t mention upfront. That integration work can easily run 30–50% of your initial platform cost.
Conclusion
Why hardware agnostic AI why Robostral Navigate’s ‘any robot fleet’ claim proves so challenging comes down to fundamental engineering realities. API fragmentation, firmware lock-in, and deployment friction create barriers that no single software layer has fully overcome — and I don’t say that to dismiss the effort involved in building these platforms.
That doesn’t mean the concept is worthless. Orchestration-level abstraction delivers real value. However, the gap between “we can monitor any robot” and “we can precisely control any robot” remains vast. Buyers who understand this distinction make better purchasing decisions and avoid some genuinely painful surprises.
Actionable next steps for your evaluation:
- Map your actual fleet composition and required capabilities before engaging vendors
- Request detailed feature matrices, not just compatibility lists
- Test with your specific robot combinations under realistic conditions
- Budget for integration engineering that vendors won’t include in quotes
- Keep native control capabilities as a fallback for each robot platform
- Revisit standards progress annually, because this space moves fast
Bottom line: the hardware agnostic AI future will eventually arrive. But it’ll come through industry standards adoption and manufacturer cooperation, not through any single vendor’s middleware claims. Stay skeptical, test rigorously, and let real-world performance — not marketing promises — guide your decisions.
FAQ
What does hardware-agnostic AI actually mean in robotics?
Hardware agnostic AI refers to software that controls robots regardless of manufacturer or model. Importantly, it aims to abstract away hardware differences behind a universal interface. Think of it as a translator between your commands and each robot’s native language. However, the depth of that translation varies enormously between platforms. Most solutions handle basic commands well but struggle with advanced, manufacturer-specific features.
Does using hardware-agnostic software void my robot’s warranty?
It depends on your purchase agreement. Nevertheless, many manufacturers include clauses that void warranties when third-party control software replaces native systems. Specifically, if the abstraction layer bypasses safety-certified firmware, you may lose both warranty coverage and safety certifications. Always review your contracts and consult your robot manufacturer before deploying third-party control layers.
How does firmware lock-in prevent true hardware-agnostic control?
Manufacturers embed proprietary optimization algorithms, safety systems, and communication protocols in firmware. These components are often encrypted or undocumented. Furthermore, safety certifications like those required by ISO standards depend on validated firmware stacks. Inserting middleware between the control software and firmware can invalidate certifications. Additionally, proprietary motion planning algorithms tuned for specific hardware can’t be replicated by generic alternatives without a real performance hit.
Are there any successful examples of hardware-agnostic robot fleet management?
Yes, but with caveats. Warehouse automation companies successfully coordinate mixed fleets of autonomous mobile robots (AMRs) from different manufacturers. Similarly, monitoring and analytics platforms work well across diverse robot types. However, these successes operate at the orchestration level, not the precision control level. Moreover, they typically handle simpler robots with fewer degrees of freedom than industrial arms. True hardware agnostic AI for precision manufacturing remains largely out of reach for now.
References
Keep reading
Here are the latest posts from the blog.

Europe just made its boldest move in the robotics race. Physical AI robots Europe Mistral Robostral Navigate represents a serious attempt to challenge American and Chinese do…

Understanding DNA storage chip architecture how electrical synthesis works is becoming genuinely essential for anyone tracking where data infrastructure is actually headed. A…

The broadcom apple expanded chip partnership through 2031 is, honestly, one of the most significant deals in a decade of covering this industry. Announced in May 2023 and val…