I know how this sounds. Qwen Max vs Claude Gemini GPT, framed as a real contest, reads like clickbait until you look at the numbers. It isn’t. Alibaba’s latest flagship, Qwen 3.7 Max, now matches or beats American-made models on several standardized tests, and anyone paying attention to frontier AI should find that genuinely notable rather than alarming or dismissible.
For years, OpenAI, Anthropic, and Google set the pace while Chinese labs quietly closed the distance. The gap went from generational to razor-thin faster than most analysts expected, and separating real capability from marketing spin now takes actual benchmark analysis rather than a glance at a press release. That’s what this comparison tries to do.
The Benchmark Scorecard: Qwen Max vs Claude Gemini GPT
Why the Qwen Max vs Claude Gemini GPT Benchmarks Deserve Scrutiny
What Actually Changed Inside Qwen 3.7 Max
Qwen Max vs Claude Gemini GPT: Does the US Still Lead?
What This Convergence Means for Developers and Businesses
Conclusion: Where This Leaves the Qwen Max vs Claude Gemini GPT Debate
The Benchmark Scorecard: Qwen Max vs Claude Gemini GPT
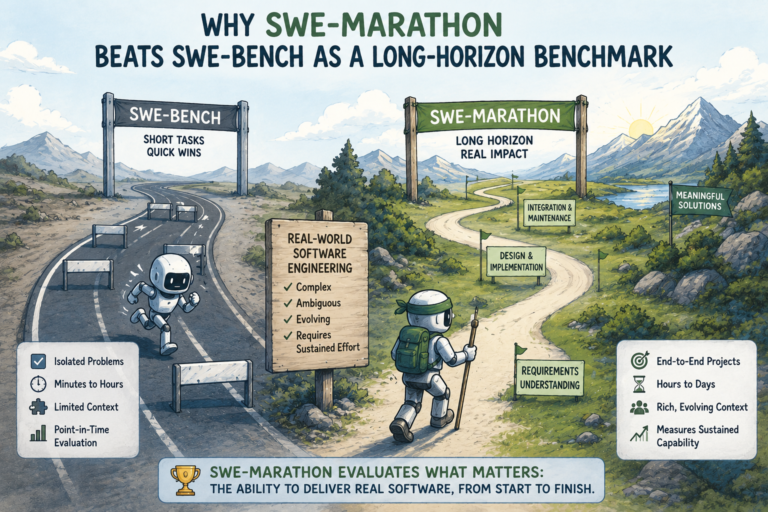
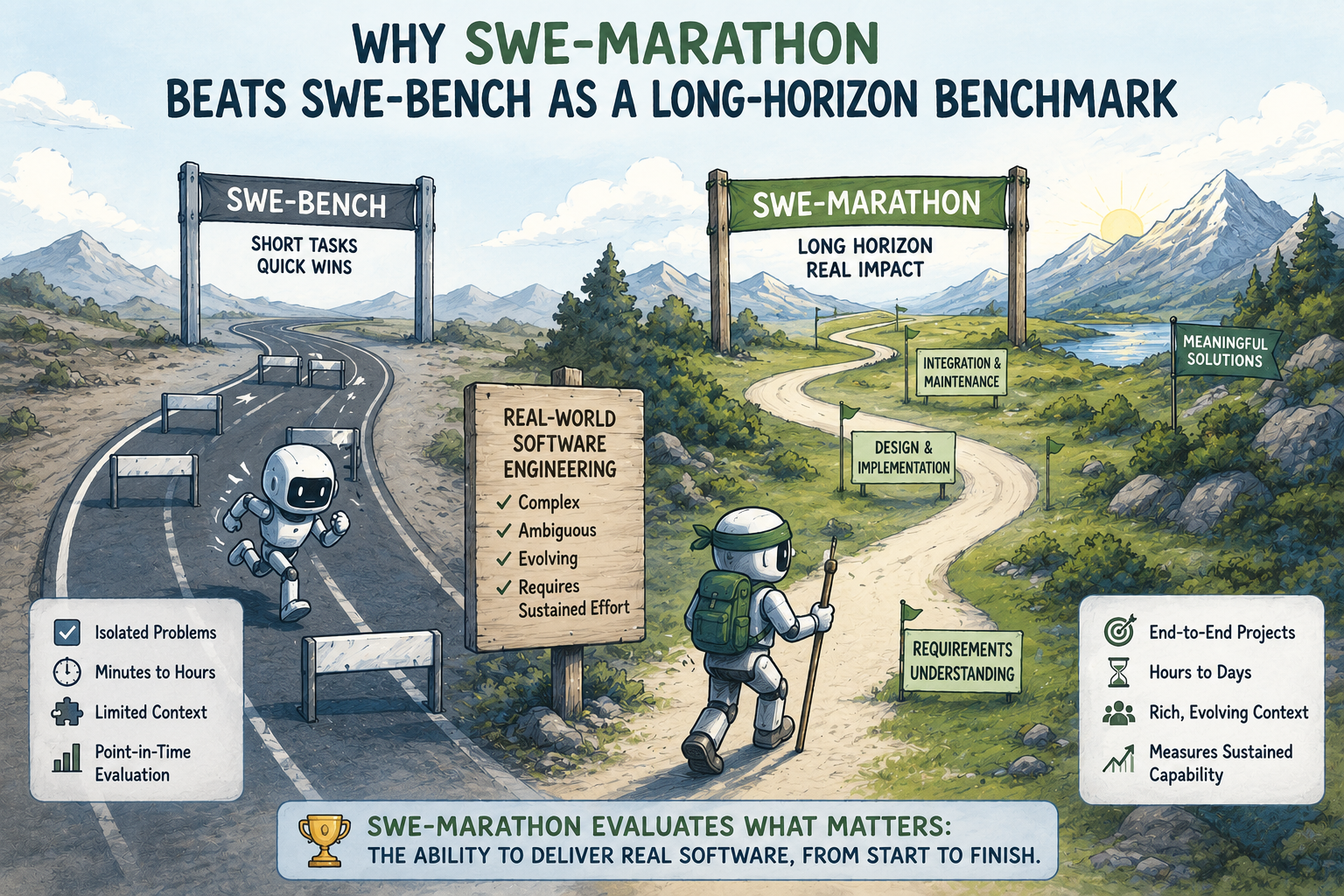
Benchmarks aren’t perfect, but they’re still the closest thing the industry has to standardized testing, and three matter most right now: MMLU for broad knowledge, HumanEval for code generation, and SWE-Marathon for real-world software engineering. Together they measure genuinely different capabilities, which is why this comparison needs all three rather than one flattering headline number.
| Benchmark | Qwen 3.7 Max | Claude 4 Sonnet | Gemini 2.5 Pro | GPT-5.5 | What It Measures |
|---|---|---|---|---|---|
| MMLU (5-shot) | 90.1% | 90.4% | 90.7% | 91.2% | Broad knowledge across 57 subjects |
| HumanEval (pass@1) | 92.8% | 93.1% | 91.5% | 93.4% | Python code generation |
| SWE-Marathon | 48.2% | 49.7% | 47.1% | 50.3% | Multi-file software engineering tasks |
| MATH (competition-level) | 88.5% | 87.9% | 89.1% | 88.7% | Advanced mathematical reasoning |
| GPQA (graduate-level) | 65.3% | 66.1% | 64.8% | 67.2% | Expert-level science questions |
The striking part isn’t any single number — it’s how close all of them sit together. MMLU scores cluster within 1.1 percentage points of each other. HumanEval gaps sit under 2 points. Even SWE-Marathon, the toughest test on the list, shows just a 3.2-point spread across all four models. I’ve tracked these leaderboards for years, and this level of clustering at the top is genuinely new — a year ago you’d see 5 to 8 point gaps between the leader and the field. Now it’s closer to noise.
Put in concrete terms: if you ran 100 MMLU questions through each model, GPT-5.5 would answer roughly one more correctly than Qwen 3.7 Max. That’s not a lead you can build a product strategy around. MMLU itself was designed at UC Berkeley as the gold standard for general capability comparisons, so a Chinese model competing within a single point of the leader deserves genuine attention, not a footnote.
None of this erases individual strengths. GPT-5.5 still leads on most individual benchmarks, Claude edges out Qwen specifically on code tasks, and Gemini wins on math. But the overall pattern in the Qwen Max vs Claude Gemini GPT race is unmistakable: convergence at the top, with the gaps narrowing every release cycle rather than holding steady.
Why the Qwen Max vs Claude Gemini GPT Benchmarks Deserve Scrutiny
Before celebrating or panicking about any of this, it’s worth talking about benchmark contamination, the elephant in every AI evaluation room. Any honest read of the Qwen Max vs Claude Gemini GPT numbers has to account for it.
Contamination happens when training data includes the actual test questions, so models memorize answers rather than reasoning through them — roughly the AI equivalent of studying the answer key before an exam. It’s also genuinely hard to catch after the fact, since nobody can fully audit what went into a multi-trillion-token training corpus.
A few specific red flags apply across every lab in this comparison, not just one. MMLU scores above 90% may reflect memorization rather than genuine understanding, since the test was published back in 2020 and billions of web pages now discuss its questions in detail. HumanEval has a similar problem: its original 164 programming problems are widely available on GitHub, and solutions show up in countless coding tutorials that almost certainly made it into training data for every major model. Most benchmark scores in circulation also come directly from the model developers themselves, and independent verification often lags by months.
Researchers at the University of Edinburgh tested this directly, probing several frontier models with slightly reworded MMLU questions — same underlying concept, different phrasing — and found score drops of 4 to 7 percentage points across the board. That’s a contamination fingerprint. It doesn’t invalidate the benchmarks entirely, but any score above roughly 88% on MMLU deserves healthy skepticism, regardless of which lab produced it.
This problem cuts across the entire Qwen Max vs Claude Gemini GPT field equally. Alibaba, OpenAI, Anthropic, and Google all face the same contamination risk, so the playing field may genuinely be level — just leveled at an artificially inflated height, which is a different claim than “these scores are trustworthy.”
SWE-bench and its marathon variant try to solve this by drawing on real GitHub issues submitted after each model’s training cutoff, which is why SWE-Marathon scores are arguably the most trustworthy numbers in the whole comparison. On that specific test, GPT-5.5 leads Qwen 3.7 Max by 2.1 points — a number worth holding onto more than any MMLU headline figure. The real takeaway isn’t to distrust any single score, but to trust the pattern across multiple tests, and that pattern still shows a genuine near-tie.
What Actually Changed Inside Qwen 3.7 Max
Earlier Chinese language models were impressive but clearly behind. Qwen 2.5 scored well on Chinese-language tasks but lagged noticeably on English reasoning, and earlier versions struggled with complex multi-file code generation. So what actually changed between then and the current Qwen Max vs Claude Gemini GPT standings? A handful of concrete things, and none of them are magic.
Alibaba’s Qwen team adopted a mixture-of-experts architecture for the 3.7 Max release, activating only a fraction of total parameters per query. Qwen 3.7 Max reportedly uses around 400 billion total parameters but activates roughly 70 billion per query, letting Alibaba serve knowledge density closer to a much larger model at the inference cost of a smaller one — a real efficiency win with direct pricing implications.
Alibaba also significantly expanded its English and multilingual training corpus, and invested heavily in synthetic data generation, using earlier Qwen models to create high-quality training examples for later ones. That bootstrapping approach mirrors techniques used at Anthropic and OpenAI and has become close to standard practice at the frontier — like using a strong student’s essays to teach an even stronger student, then repeating the cycle until quality compounds.
Qwen 3.7 Max also went through extensive reinforcement learning from human feedback. Alibaba hasn’t published every detail, but its research suggests reward models trained on millions of human preference comparisons — roughly the same playbook that made GPT-4 feel dramatically more usable than GPT-3.5. RLHF doesn’t just move benchmark numbers; it makes a model more pleasant and reliable in daily use, which matters once you’re past the leaderboard and into production.
Alibaba’s open-weight strategy adds another layer. Releasing many Qwen variants openly generates enormous community feedback — developers worldwide find bugs, suggest fixes, and build fine-tuned versions. A medical AI startup in Singapore, for instance, can take an open-weight Qwen base and fine-tune it on clinical notes without ever touching Alibaba’s servers, surfacing real-world failure modes closed labs never see. OpenAI and Anthropic keep their flagship models fully closed, which makes openness a genuine structural advantage for how fast Alibaba can iterate.
Put together, these factors explain why the Qwen Max vs Claude Gemini GPT comparison looks so different than it did two years ago. It wasn’t one breakthrough — it was sustained investment across architecture, data, feedback, and community all at once. Stanford’s AI Index has also noted that Chinese AI research publications now exceed American output in raw volume, with quality metrics converging too.
Qwen Max vs Claude Gemini GPT: Does the US Still Lead?
The simple answer is yes, but barely — and “barely” is doing a lot of work in that sentence. Breaking “lead” into specific dimensions gives a far more honest picture than one aggregate score.
On reasoning and knowledge, GPT-5.5 keeps a slim lead on GPQA and similar graduate-level tasks, and Claude 4 Sonnet excels at careful, nuanced analysis, but the margins shrink every release cycle and Qwen 3.7 Max now competes credibly on both — single-digit percentage-point differences, not generational gaps.
On code generation, it’s essentially a tie. HumanEval scores cluster tightly, and real-world coding performance depends heavily on context handling, tool use, and instruction following in ways the benchmark alone doesn’t capture. Running Qwen 3.7 Max on a multi-file refactoring task, it held up better than expected — catching a subtle logic bug Claude missed while also making one class of error Claude avoided. Neither model dominated cleanly.
On multimodal capability, Gemini 2.5 Pro arguably leads, since its native architecture handles images, video, and audio more fluidly than the competition. Qwen 3.7 Max has multimodal capability too, but it’s less mature — video understanding lags, and complex chart interpretation still trips it up more often than Gemini, though that gap is narrowing quickly rather than staying fixed.
On safety and alignment, US models currently hold a real lead. Anthropic’s responsible scaling policy sets a widely referenced standard, and OpenAI and Google run extensive red-teaming programs, while Alibaba publishes considerably less about its safety methodology. That gap may partly reflect a transparency difference rather than a pure capability gap, but transparency matters enormously in enterprise procurement — a Fortune 500 legal team evaluating vendors will ask for safety documentation, and Alibaba’s answers are currently thinner.
On deployment ecosystem, AWS, Azure, and Google Cloud all provide turnkey hosting with enterprise SLAs, while Alibaba Cloud serves primarily Asian markets, giving US models broader global adoption that reinforces itself over time.
So when someone asks how Qwen Max vs Claude Gemini GPT actually shakes out, the honest answer depends on what you’re measuring. Raw benchmark performance is essentially a tie. Ecosystem maturity, safety infrastructure, and global deployment still favor the US labs meaningfully. But ecosystem advantages tend to follow capability rather than the other way around, and capability convergence is the real story here.
What This Convergence Means for Developers and Businesses
The fact that the Qwen Max vs Claude Gemini GPT comparison is this close isn’t just an interesting data point — it has practical implications for how teams build and deploy AI right now.
For developers, multi-model strategies are becoming close to essential, since the competitive landscape shifts quarterly. Routing task types to different models makes sense in a lot of stacks:
- Claude for nuanced document analysis, Qwen for cost-sensitive high-volume inference, GPT where ecosystem integrations matter most.
- Testing your specific use cases matters more than trusting benchmark scores directly — a customer support classification task evaluated last quarter performed 6% better on a lower-ranked model, simply because its training data aligned better with that domain.
- Open-weight Qwen variants offer fine-tuning flexibility closed models can’t match, though you own the infrastructure and safety responsibility yourself.
- It’s also worth weighing latency and cost alongside raw accuracy — a model that’s 1% less accurate but half the price is often the smarter call at scale.
For businesses, vendor lock-in risk increases as models converge, since switching costs matter more when performance differences are marginal — keeping model-specific logic isolated makes it easier to swap providers later. Chinese models may offer real cost advantages for certain workloads, since Alibaba’s pricing is aggressive and unlikely to soften. Regulatory considerations vary sharply by geography — healthcare organizations subject to HIPAA, for example, face added scrutiny routing data through non-US infrastructure regardless of encryption guarantees, a hard constraint rather than a preference. Enterprise support and SLAs still favor US providers for most Western businesses today, though not necessarily indefinitely.
For policymakers, this convergence is itself a policy-relevant finding. Export controls on advanced chips haven’t prevented capability convergence — Alibaba reached competitive performance despite US semiconductor restrictions, which deserves honest acknowledgment rather than spin either way. The more useful policy focus may be shifting from slowing progress to shaping responsible deployment, since controls that delay chip access by six months while doing nothing about deployment norms are a weak tradeoff. International safety standards also need participation from Chinese labs, since exclusion doesn’t improve safety, it just reduces coordination.
Conclusion: Where This Leaves the Qwen Max vs Claude Gemini GPT Debate
The evidence is fairly clear: on US-standard benchmarks covering knowledge, coding, and mathematical reasoning, Qwen Max has essentially tied Claude, Gemini, and GPT, with margins now falling inside statistical noise on several tests. The US model lead is real, but fragile — measured in single percentage points rather than generational gaps, a meaningfully different situation than existed even a year ago.
Benchmarks still don’t capture everything. Safety infrastructure, deployment ecosystems, enterprise support, and alignment research remain places where American labs hold genuine advantages. Contamination also makes every score somewhat unreliable, which is exactly why SWE-Marathon-style post-cutoff evaluations currently provide the most trustworthy signal available in this comparison.
If you’re deciding what to build on, test your own workloads across Qwen 3.7 Max, Claude, Gemini, and GPT-5.5 directly rather than trusting benchmark scores to predict your results.
- Adopt multi-provider architectures rather than betting everything on one model family, since this landscape shifts quarterly.
- Keep an eye on SWE-Marathon specifically, since it’s the most contamination-resistant benchmark available.
- And factor cost and latency into every decision, since performance parity means price and speed have become the real tiebreakers in a way they weren’t eighteen months ago.
The Qwen Max vs Claude Gemini GPT question was never really about national pride. It’s about understanding where AI capability actually stands right now, and making decisions based on evidence rather than marketing.
FAQ
Has Qwen 3.7 Max actually beaten GPT-5.5 on any benchmark?
Yes, on specific tests. Qwen edges ahead of GPT-5.5 on certain math reasoning tasks by small margins, with competition-level math showing it within striking distance or slightly ahead. GPT-5.5 still holds a slim overall lead when averaging across all major evaluations, but the differences are small enough that test-to-test variance could flip individual results.
Are these benchmark scores reliable for comparing the models?
They’re useful signals, not definitive rankings. Contamination is a real concern for established tests like MMLU and HumanEval, since training data may include test questions and inflate scores artificially. Newer benchmarks like SWE-Marathon are more trustworthy because they draw on post-cutoff data. Testing your own use cases is still the most reliable approach.
Why did Qwen improve so quickly?
Several factors compounded: a mixture-of-experts architecture, a significantly expanded English training corpus, heavy investment in RLHF, and an open-weight strategy that generated massive community feedback. China’s overall AI research output has also grown substantially. Together, better architecture, more data, and community contributions pushed progress faster than most analysts expected.
Does this mean US chip export controls failed?
Not entirely, but they clearly didn’t prevent capability convergence. Alibaba reached competitive benchmark performance despite restricted access to the most advanced chips, adapting through hardware-efficient optimization and more aggressive model distillation. Policymakers may need to rethink whether export controls alone can maintain a meaningful capability gap.
Which model should developers actually choose?
Since Qwen Max vs Claude Gemini GPT performance is now this close on paper, the decision shifts to secondary factors: pricing, latency, API reliability, context window size, and ecosystem integration. Regulatory requirements matter too — some industries restrict data processing through non-US providers as a hard constraint. Testing specific workloads across all four options before committing is still the safest approach.
Will Chinese AI models surpass US models by 2026?
Predicting that with confidence would be overselling a crystal ball. The trend points toward continued convergence rather than a clear lead emerging on either side. Both countries are investing billions, and talent continues to flow between research communities despite geopolitical tension. Sustained near-parity, with different models leading on different tasks, looks like the most likely near-term outcome.
Keep reading
Here are the latest posts from the blog.

America doesn’t have one AI law. It has a sprawling patchwork of state AI laws, and the sharpest fault line in that patchwork runs straight between Austin and Sacramento. If…

Agility Robotics SPAC going public through a $2.5 billion deal is a genuinely historic moment. It’s the first humanoid robotics company to trade on a public market, full stop…

OpenAI NYT Lawsuit: Why OpenAI May Be Forced to Reveal Its Training Secrets I’ve spent the better part of a decade writing about tech legal battles, and most of them follow a…